Windows Memory Protection Mechanisms

Introduction
When trying to protect memory from being maliciously used by the hackers, we must first understand how everything fits in the whole picture. Let's describe how a buffer overflow is exploited:

Become a certified reverse engineer!
- Finding Input Shellcode Address—When we send input data to the application, we must send data that will cause a buffer overflow to be triggered. But we must write the input data in such a way that we'll include the address that points to our shellcode that was also input as part of the input data. This is needed so the program execution can later jump to the shellcode by using that shellcode memory address pointer.
- Data Structure Overwrite—In order for the program to actually jump to our shellcode, we must overwrite some data structure where the address is read from and jumped to. An example of such a structure is a function frame that's stored on the stack every time a function is called; besides all the other stuff stored on the stack, one of them is also the return EIP address where the function will return when it's done with the execution. If we over write that address with the address of our shellcode in memory, the program execution will effectively jump to that address and execute our shellcode.
- Finding the System Function's Address—When our shellcode is being executed, it will often call various system functions, which we don't know the addresses of. We can hardcode the addresses of the functions to call in the shellcode itself, but that wouldn't be very portable and it often won't work on modern systems because of the various memory protection mechanisms in place. In order to find the addresses of the functions that we want to call, we must dynamically find them upon the shellcode execution.
We must mention that if only one of the above conditions is not true, then the buffer exploitation will fail and we won't be able to execute our shellcode. This is an important observation because, if we're not able to satisfy every condition, the exploit will not work and the attack will be prevented. Next, we'll discuss the techniques we can use to prevent one (or many) of the above conditions from being satisfied by malicious hackers. Let's mention it again: If we're able to prevent hackers from satisfying at least one of the above conditions, then the exploitation of the buffer overflow will fail. This is why we'll take a look at methods of preventing each of the conditions from being satisfied. Let's not forget about the conditions where the buffer is very small and we can't actually exploit the condition in one go, but we must send multiple packets to the target in order to successfully exploit it;; one such technique is the egg-hunting exploitation technique, where we first inject some malicious code into the process's memory, which contains an identifiable group of bytes often referred to as an egg. After, that we need to inject a second (and possibly a third, fourth, etc.) input into the process, which actually exploits and overwrites the return EIP address. Thus, we can jump to the first part of the shellcode, which must find the egg in memory and continue the execution from there – this is the shellcode we've inputted into the process's memory with the first packet. We must keep in mind that in all of those special cases, the above conditions must still hold, which is also the reason we'll be examining them in more detail later in the article.
I guess we can also mention that none of the exploitation techniques would be possible if programmers would write safe code without bugs. But because life is not perfect, bugs exist and hackers are exploiting them every day. Because of that, whitehat hackers have come up with various ways to prevent the exploitation of bugs even if they exist in the code: some of the techniques can be easily bypassed but others are very good at protecting the process's memory.
Techniques for Protecting the Finding of Input Shellcode Address
When exploiting a service, we're sending input data to the service, which stores it in a buffer. The input data usually contains bytes that represent native CPU instructions. The buffer where our input bytes are written to can be located anywhere in memory:
- on the stack
- on the heap
- in the static data area (initialized or uninitialized).
Currently, the following methods prevent us from guessing the right input address, which we can use to overwrite some important data structure that enables us to jump to our shellcode. These methods are:
- Instruction set randomization: read this article.
- Randomizing parts of the operating system – ASLR: read this article.
We need to overwrite the return address EIP or some other similar structure to jump to some instructions in memory that can help us eventually jump to our shellcode. This is why we need to overwrite the structure with something meaningful, like an address that can take us to our shellcode and execute it. There are possibly infinite possibilities of how we can do that, but let's list just a few of them to get an idea how this can be done:
- call/jmp reg—We're using the register that contains the address of our shellcode, which we're calling to effectively execute that shellcode. We can find either the "call reg" or "jmp reg" in one of the libraries the program needs to execute in order to jump to the shellcode. Note that this only works if one of the registers contains an address that points somewhere into the shellcode.
- pop ret—If we cannot use the previous option because none of the registers point somewhere in our shellcode, but there's an address that points to the shellcode written on the stack somewhere, we can use multiple pop and one ret instruction to jump to that address.
- push ret—If one of the registers points somewhere in our shellcode, we can also use the "push ret" instruction. This is particularly good if we cannot use the "call/jmp reg," because we're unable to find the appropriate jmp/call instructions in the loaded libraries. To solve that, we can push the address on the stack and then return to it by using the push reg and ret instructions.
- jmp [reg + offset]—We can use this instruction if there's a register that points to our shellcode in memory, but doesn't point to the beginning of our shellcode. We can try to find the instruction "jmp [reg+offset]," which will add the required bytes to the register and then jump to that address, presumably to the beginning of our shellcode.
- popad—The "popad" instruction will pop double words from the stack into the general purpose registers EDI, ESI, EBP, EBX, EDX, ECX and EAX. Also, the ESP register will be incremented by 32. By using this technique, we can make the ESP register point directly to our shellcode and then issue the jmp esp instruction to jump to it. If the shellcode is not present at the 32-byte boundary, we can add a number of nop instructions at the beginning of our shellcode to make it so.
- forward short jump (jmp num)—We can use forward short jump if we want to jump over a couple of bytes. The opcode for the jmp instruction is 0xeb, so if we would like to jump over 16 bytes, we could use the 0xeb,0x10 instructions. We could also use conditional jump instructions, where just the opcode is changed.
- backward short jump (jmp num)—This is the same as forward short jump, except that we would like to jump backward. We can do this by using a negative offset number, where the 8-bit needs to be 1. If we would like to jump 16 bytes back, we could use the following instructions 0xeb,0x90.
- SEH—Windows applications have something called a default exception handler, which is provided by the operating system. Even if the application doesn't use exception handling, we can try to overwrite the SEH handler and then generate some exception, which will call that exception handler. Since we've overwritten the exception handler with the pointer to our shellcode, that will be executed when an exception occurs.
Techniques for Protecting Data Structure Overwrite
One of the conditions already mentioned was that if we can overwrite certain data structure, we might be able to gain control of the program and possibly the whole system. The data structures that we can overwrite are the following:
- EIP in Stack Frame—When a function is called, it is stored a function frame on the stack, which also contains the EIP that points to the next instruction after the function call, which is required so that the function knows where to return to. If we overwrite the EIP return address, we'll be able to jump and execute the instruction on the arbitrary memory address.
- Function Pointers—We can also overwrite a function pointer that points to a function on the heap. If we overwrite the function pointer to point to our shellcode somewhere in memory, that shellcode will be executed whenever the function is called (the one whose pointer address we've overwritten). Keep in mind that function pointers can be allocated anywhere in memory, on stack, heap, data, etc.
- Longjmp Buffers—The C programming language has something called a checkpoint/rollback system called setjmp/longjmp. The basic idea is to use the setjmp (buffer) to go to checkpoint and then use the longjmp (buffer) to go back to the checkpoint. But if we manage to overflow the buffer, the longjmp (buffer) might jump back to our shellcode instead.
- SEH Overwrite—We can overwrite stack exception handling structures stored on the stack, which can allow us to gain code execution when an exception occurs.
- Program Logic—With this attack, we're overflowing the arbitrary data structure that a program uses incorrectly: by possibly executing the inputted shellcode. This is a really rare occurrence of a bug, but is still possible.
- Other—There are other structures that we can overwrite to gain code execution as well.
We can use the following techniques to defend the data structures (summarized from [1]):
- Non-Executable Stack—If the stack is non-executable, then we won't be able to execute the code written to the stack. This protection is very effective against stack buffer overflow attacks, but doesn't protect us from overflowing other data structures and executing the shellcode from there.
- DEP (Data Execution Prevention)—When DEP is enabled, we can't execute the code from pages that are marked as data. This is an important observation, because with typical problems the code is not contained and executed from stack or heap structures, which typically contain only data.
- Array Bounds Checking—With this prevention mechanism, the buffer overflows are completely eliminated, because we can't actually overflow an array, since the bounds are being checked automatically (without user intervention). But this approach rather slows down the program execution, since every access to an array must be checked to see if it's within the bounds.
- Code Pointer Integrity Check—This protection provides a way to check whether the pointer has been corrupted before trying to execute the data from that address.
DEP (Data Execution Prevention)
We've already mentioned that DEP allows the pages in memory to be marked as non-executable, which prevents the instructions in those pages to be executed (usually the stack and heap data structure are used with DEP enabled). If the program wants to execute code from the DEP-enabled memory page, an exception is generated, which usually means the program will terminate. The default setting in a Windows system is that DEP is enabled. To check whether DEP is enabled, we must look into the C:boot.ini configuration file and look at the /noexecute flag value. The values of the /noexecute switch can be one of the following values:
- OptIn—DEP enabled for system modules, but user applications can be configured to also support DEP
- OptOut—DEP enabled for all modules and user applications, but can be disabled for certain user applications
- AlwaysOn—DEP enabled for all modules and all user applications and we can't switch it off for any user application
- AlwaysOff—DEP disabled for all modules and all applications and we can't switch it on for any user application or any system module
We can see that with OptIn and OptOut options, we can dynamically change whether the DEP is enabled or disabled for certain user applications. We can do that with the use of the SetProcessDEPPolicy system function. The syntax of the function is presented below (taken from [2]):
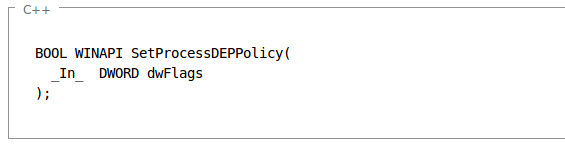
The SetProcessDEPPolicy function overrides the system DEP policy for the current process unless its DEP policy was specified at process creation. The system DEP policy setting must be OptIn or OptOut. If the system DEP policy is AlwaysOff or AlwaysOn, SetProcessDEPPolicy returns an error. After DEP is enabled for a process, subsequent calls to SetProcessDEPPolicy are ignored [2].
The dwFlags parameter can be one of the following:
- 0—Disables the DEP for the current process if system DEP policy is either OptIn or OptOut.
- 1—Enables the DEP permanently for the current process.
We can enable/disable DEP for certain user applications if we right-click on My Computer, then go to Advanced and click on Performance Settings – Data Execution Prevention, we see picture below:
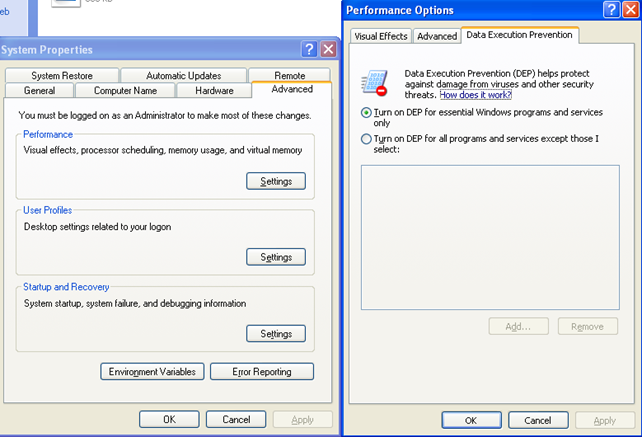
Currently the OptIn is set in the C:boot.ini, which resembles the options specified above. If DEP was disabled, the options above would be grayed out: they are only enabled when OptIn or OptOut is being used. Let's change the DEP configuration option to OptOut in the Performance Options window and also add an exception so that iexplore.exe won't have DEP enabled. We see the picture below:
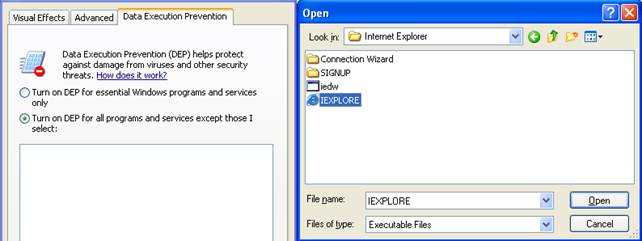
Once we click on the Open button, the IEXPLORE.EXE will be added to the list of user applications that have DEP disabled, which can be seen in the picture below:

Once we try to save the settings, a warning will pop-up notifying us that we must restart the computer in order for changes to take effect:
We must click on OK and then restart the computer. Then we can open two processes, explorer.exe and opera.exe and observe their DEP settings in the Windbg kernel debugger. Then we need to execute the "!process 0 0" command to display the details about every process running on the system. The information about the explorer.exe and opera.exe are shown below:
[plain]
kd> !process 0 0
PROCESS 821dc620 SessionId: 0 Cid: 05c0 Peb: 7ffd9000 ParentCid: 05cc
DirBase: 093c0180 ObjectTable: e1827200 HandleCount: 288.
PROCESS 822d2948 SessionId: 0 Cid: 05c8 Peb: 7ffdf000 ParentCid: 05cc
DirBase: 093c0280 ObjectTable: e1de34b8 HandleCount: 563.
Image: IEXPLORE.EXE
The !process command is a good way to get the pointer to the EPROCESS data structure of each process: the pointer to the opera.exe EPROCESS data structure is 0x821dc620, while the pointer to the IEXPLORE.EXE EPROCESS data structure is 0x822d2948. Let's now show the EPROCESS data structure of each of the processes:
[plain]
kd> dt nt!_EPROCESS 821dc620
+0x000 Pcb : _KPROCESS
+0x06c ProcessLock : _EX_PUSH_LOCK
+0x070 CreateTime : _LARGE_INTEGER 0x01ce1da6`e74feeaa
+0x078 ExitTime : _LARGE_INTEGER 0x0
+0x080 RundownProtect : _EX_RUNDOWN_REF
kd> dt nt!_EPROCESS 822d2948
+0x000 Pcb : _KPROCESS
+0x06c ProcessLock : _EX_PUSH_LOCK
+0x070 CreateTime : _LARGE_INTEGER 0x01ce1da6`e7a8e488
+0x078 ExitTime : _LARGE_INTEGER 0x0
+0x080 RundownProtect : _EX_RUNDOWN_REF
+0x084 UniqueProcessId : 0x000005c8 Void
I didn't present the whole output from that command, because the output is too long and we're not interested in the rest of the output right now. We're only interested in the first element of the EPROCESS structure, which is the KPROCESS data substructure, as we can see above. Since the first element of the EPROCESS data structure is the KPROCESS data structure, we can display that with the same memory address as we used when printing the EPROCESS data structure. We can also use the -r switch to the command to go into every substructure of the KPROCESS structure and display all of the known elements. There are a lot of members of the KPROCESS data structure, which is why we'll only be showing the most important ones (in the output below we presented only the Flags data member):
[plain]
kd> dt nt!_KPROCESS 821dc620 -r
+0x06b Flags : _KEXECUTE_OPTIONS
+0x000 ExecuteDisable : 0y1
+0x000 ExecuteEnable : 0y0
+0x000 DisableThunkEmulation : 0y1
+0x000 Permanent : 0y1
+0x000 ExecuteDispatchEnable : 0y0
+0x000 ImageDispatchEnable : 0y0
+0x000 Spare : 0y00
kd> dt nt!_KPROCESS 822d2948 -r
+0x06b Flags : _KEXECUTE_OPTIONS
+0x000 ExecuteDisable : 0y0
+0x000 ExecuteEnable : 0y1
+0x000 DisableThunkEmulation : 0y0
+0x000 Permanent : 0y0
+0x000 ExecuteDispatchEnable : 0y1
+0x000 ImageDispatchEnable : 0y1
+0x000 Spare : 0y00
+0x06b ExecuteOptions : 0x32 '2'
The important flags that we're interested right now are the ExecuteDisable and ExecuteEnable. The ExecuteDisable flag is set to 1 whenever DEP is enabled, while the ExecuteEnable flag is set to 1 whenever DEP is disabled. Also the Permanent flag is set to 1 if the process cannot change the DEP policy by itself. Let's review the settings of both processes, the IEXPLORE.EXE and opera.exe:
We can see that the options are exactly the opposite for those two processes. The IEXPLORE.EXE process has DEP disabled, because the ExecuteDisable is set to 0 and ExecuteEnable is set to 1, while the opera.exe has DEP enabled, because the ExecuteDisable is set to 1 and ExecuteEnable is set to 0. The IEXPLORE.EXE has DEP disabled only because we've added the exception to the OptOut system DEP policy.
Address Space Layout Randomization (ASLR)
The Windows systems use PE headers to describe the executable files. One of the elements of the PE header is the preferred load address that is stored in the ImageBase element in the optional header. The address stored in the ImageBase is the linear address where the executable will be loaded if it can be loaded there (by default this address is 0x400000).
For the next test, you have to have the Sysinternals Suite downloaded, particularly the listdlls.exe program. Let's start the notepad.exe process and then execute the "listdlls.exe notepad.exe" program, which will list all the loaded DLLs from the notepad.exe program. The output can be seen below:
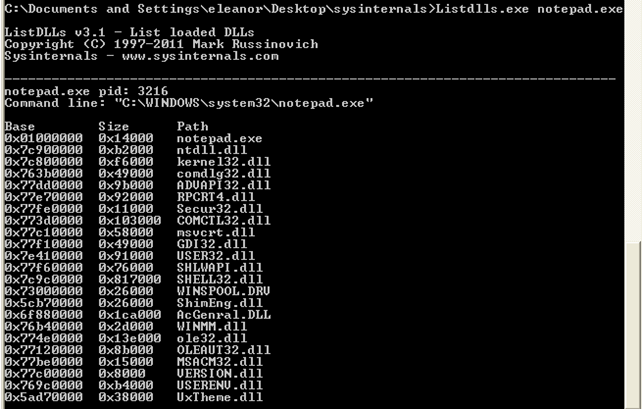
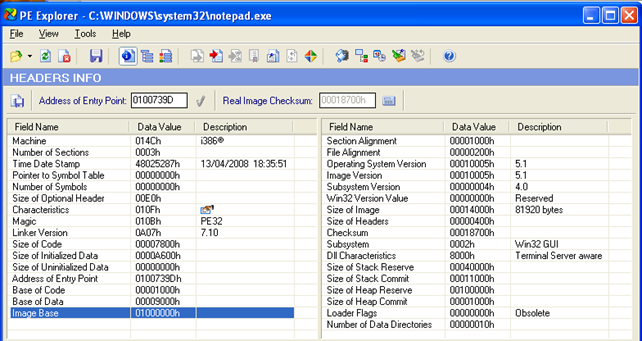
We can see that the notepad.exe executable is loaded at the default virtual/linear address 0x01000000, which is not the default address 0x400000. Actually, the 0x01000000 is the default address where libraries are loaded. Let's download the trial version of PE Explorer and open the notepad.exe executable into it. Now let's take a look at the ImageBase element, which can be seen in the picture below: it has a value 0x01000000, which is also the preferred address of where the notepad.exe will get loaded into memory:
Now we need to restart the system and use the listdlls.exe program again to list all the DLLs loaded in the notepad.exe program. The result can be seen in the picture below:
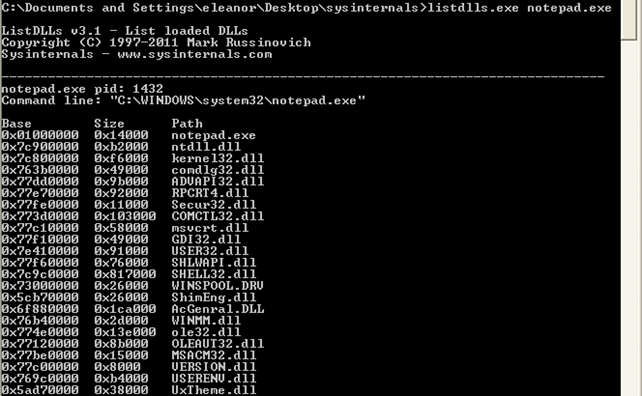
Notice that the base address of the notepad.exe and every corresponding library is the same? Because of this, exploit writing has been very successful in the last couple of years. The reason is that hackers could use a hardcoded address in their exploits, which would work on various versions of Windows systems, because the virtual/linear addresses of the programs are always the same. Windows Vista presented a concept known as address space layout randomization or ASLR that loads the executables and libraries that support ASLR at arbitrary base address every time the system reboots. This makes it difficult to hardcode the addresses in the exploits, but it is still possible. The reason is the executable and all the libraries the process uses must be compiled with ASLR enabled, but this often isn't so. The developers almost never compile the executable with ASLR enabled, and even some system libraries provided by Microsoft are not always compiled with ASLR enabled. But the attacker needs only one address to be at a constant place (even when the operating system is rebooted) in order to exploit a buffer overflow (or some other bug); thus he only needs one executable or one loaded library file to not be compiled with ASLR enabled. But because it's still often the case that at least some library doesn't support ASLR, ASLR protection is rather easy to bypass and thus not really effective.
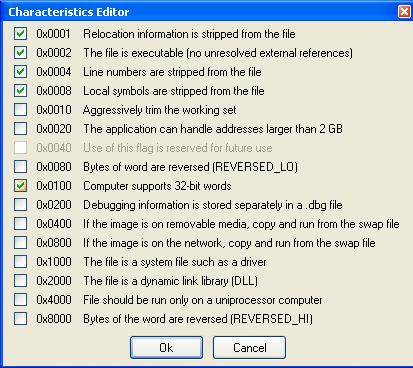
If we click on the Characteristics element in PE Explorer, we can see that the 0x0040 field is currently being used to specify whether the library was compiled with ASLR support, is marked as "Use of this flag is reserved for future use". This clearly means that the ASLR is disabled and not available for the notepad.exe, as we already saw previously.
But ASLR can nevertheless be enabled system-wide by adding the MoveImages registry key to the HKLMSYSTEMCurrentControlSetControlSession ManagerMemory Management. We can do that by adding a new DWORD value, setting the key to the MoveImages and the value to 0xFFFFFFFF. This can be seen in the picture below, where the MoveImages key has been added to the registry:
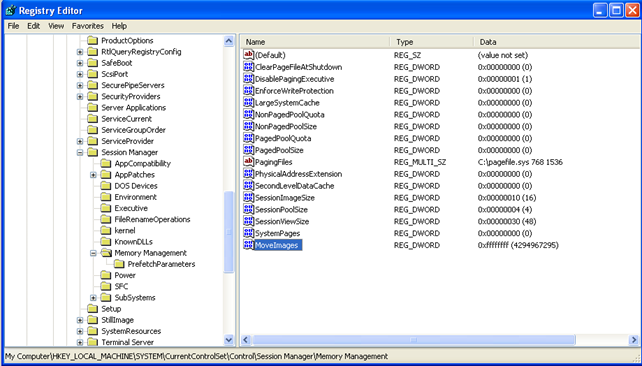
Upon adding the MoveImages key, we need to restart the computer. Then we can again execute the "listdlls.exe notepad.exe" program to check the base addresses of loaded libraries:
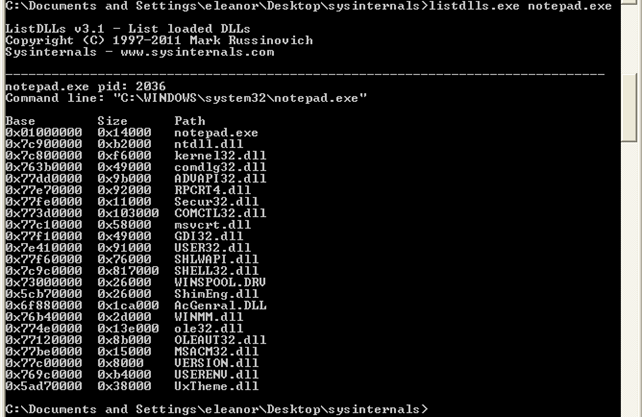
Notice that the base addresses are the same even though we've added the MoveImages to the registry. The problem is that Windows XP doesn't support ASLR, which is one reason among many to switch to a newer system, such as Windows Vista or Windows 7. But ASLR doesn't affect only the base address where the libraries are loaded, but also the base address of stack, heap and other stuff that must be loaded into memory. But the DLL libraries are loaded at the same address regarding of the process using them; this is set up during the boot process of Windows.
Let's now start the Windows 7 system and check the base addresses of modules in Ollydbg when loading the notepad.exe executable. The modules and their corresponding base addresses can be seen in the picture below:
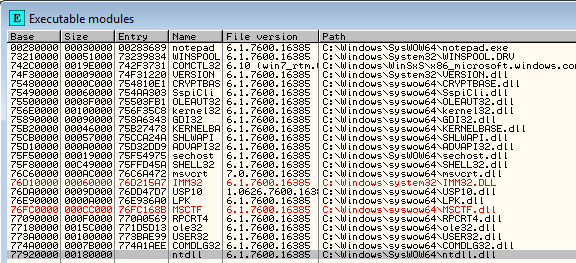
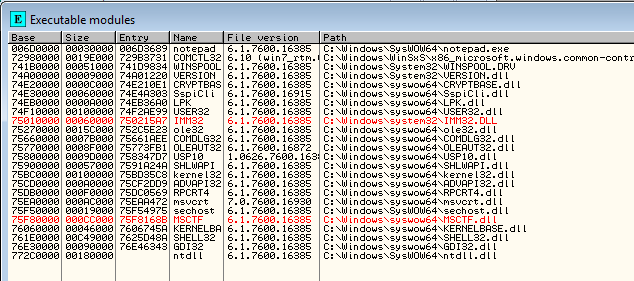
After that we can restart Windows, and reopen notepad.exe in Ollydbg. Let's list the modules again. Notice that the modules have been loaded at different base addresses? This is the effect of the ASLR being enabled. Now whenever we want to hardcode the address in shellcode, the address will be wrong after restarting the system, because the base address of the modules is at a different location; this means that the hardcoded address will not point to a different instructions in memory (if that memory is even loaded into the memory user address space).
References:
[1] StackGuard: Automatic Adaptive Detection and Prevention of Buffer-Overflow Attacks, Crispin Cowan, Calton Pu, Dave Maier, Heather Hinton, Jonathan Walpole, Peat Bakke, Steave Beattie, Aaron Grier, Perry Wagle and Qian Zhand, San Antonio, Texas, January 26-29, 1998.

[2] SetProcessDEPPolicy function (Windows), accessible at http://msdn.microsoft.com/en-us/library/windows/desktop/bb736299(v=vs.85).aspx.
- Exam Pass Guarantee
- Live expert instruction
- Hands-on labs
- CREA exam voucher
In this Series
- Windows Memory Protection Mechanisms
- Kali Linux: Top 8 tools for reverse engineering
- Stacks and Heap
- Top 8 reverse engineering tools for cyber security professionals [updated 2021]
- Arrays, Structs and Linked Lists
- Reverse engineering obfuscated assemblies [updated 2019]
- Crack Me Challenge Part 4 [Updated 2019]
- Writing windows kernel mode driver [Updated 2019]
- Assembly programming with Visual Studio.NET
- The basics of IDA pro
- Reverse engineering tools
- Hacking tools: Reverse engineering
- Reverse engineering a JavaScript obfuscated dropper
- Reverse Engineering – LAB 3
- Exploiting Protostar – Stack 0-3
- Reversing Binary: Spotting Bug without Source Code
- Reverse engineering virtual machine protected binaries
- Introduction to Reverse Engineering
- Pafish (Paranoid Fish)
- Extending Debuggers
- Encrypted code reverse engineering: Bypassing obfuscation
- Buffer Overflow Attack & Defense
- Invoking Assembly Code in C#
- iOS Application Security Part 32 - Automating tasks with iOS Reverse Engineering Toolkit (iRET)
- Hooking IDT
- A Guide to Debugging Android Binaries
- Kernel debugging with Qemu and WinDbg
- Shared Folders with Samba and Qemu
- Testing Hooks via the Windows Debugger – An Introduction to RevEngX
- Reverse Engineering with Reflector
- Applied Reverse Engineering with IDA Pro
- Injecting spyware in an EXE (code injection)
- Disassembler Mechanized Part 4: DLL Injector Development
- Disassembler Mechanized Part 3: Code Injection Operation
- Debugging TLS callbacks
- Disassembler Mechanized Part 2: Generating C# and MSIL code
- System address map initialization in x86/x64 architecture part 2: PCI express-based systems
- Coding of Disassembler
- Applied cracking & byte patching with IDA Pro
- .NET reversing with Reflexil
- Reversing firmware part 1
- Reverse Engineering with Reflector: Part 1
- Remoting Technology
- Reverse engineering with OllyDbg
- Understanding Session Fixation
- Optimizing Managed Code Execution
- File system manipulation
- The BodgeIt store part two
- The BodgeIt store part one
- Understanding Windows Internal Call Structure
- Pin: Dynamic Binary Instrumentation Framework

Get certified and advance your career
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, (ISC)², Cisco, Microsoft and more!

Reverse engineering
Reverse engineering
Reverse engineering
Top 8 reverse engineering tools for cyber security professionals [updated 2021]
Reverse engineering