Linux Kernel Development Process

Introduction
When I was listening to the question and answer session at LinuxCon, there was some interesting discussion going on: some of the latest news information is Linus Torvals's joke about putting a backdoor into the Linux operating system. The reason I started writing this tutorial is because I've been an advanced user of Linux for 10 years now; I've been working with various distributions in my free time; I've also used Linux From Scratch (LFS) a while back, which doesn't directly indicate the level of my knowledge about Linux operation system, but we can nevertheless get the picture that I'm not a newbie when it comes to Linux. Not being a newbie and a complete Linux freak, I was kind of astonished that over and over again the speakers were talking about various participants and contributors to the Linux kernel. I was thinking about what the hell am, I doing not knowing how the process works. I'm an advanced Linux user and I don't know that, oh my God. This was the reason I started looking into the kernel development and patch submissions; I wanted to know how the process works, so I can help out whenever time permits. Below I've written my observations about the process of Linux kernel patch submission.

Become a certified reverse engineer!
I've been working through various documentation about Linux kernel development process lately and the thing that I think scares people off are sentences like the following: "You should have deep understanding of Linux kernel, C programming language as well as Git version control if you want to become a kernel developer, but this is not what we're going to talk about in this presentation.". Those concepts are so vast they simply cannot be understood in a 45-minute video, neither should the speakers try to present them quickly. Nevertheless, it's a good thing to understand that you cannot simplly become a kernel developer over night; you should have at least an some knowledge about Linux kernel, C programming language and Git version control if you want to start with the kernel development process. If not, you can always learn those concepts first and then start helping out the community; it's always good to know about Linux kernel, C and Git.
Keep in mind that this tutorial is a written overview of Greg's video accessible at [1] and is kind of an additional reference the people can turn to in order to become Linux kernel developers.
Getting the Kernel Source Code and Configuring the Kernel
The very first thing that we need to do is get the latest kernel source code from the Linus Torvalds Github profile. To do that you need to use the git clone command to clone the repository to Linux-latest directory on the local host.
[plain]
# git clone https://github.com/torvalds/linux linux-latest
# cd linux-latest/
The cloning process will take quite some time since the Linux kernel is quite bit, so be patient and grab a cup of coffee while waiting. Currently the entire Linux kernel is approximately 1GB in size. After that let's go into the Linux directory and issue a "git pull" and "git status" command just to make sure that we're working with the latest source code (we should be, since we just cloned it). But if we've cloned the Linux source code a while back and we would like to bring in the latest changes, running those two commands will do the trick.
[plain]
# git pull
# git status
After we've downloaded the kernel, we still need to build it with one of the commands below:
- make config: this will give us an option to set every configuration option in the Linux kernel; since the kernel is so big, we really don't want to use this command.
- make oldconfig: takes .config file and only asks the questions that were not already present in that file.
- make menuconfig: presents a ncurses window inside a console, where we can configure our kernel the way we want.
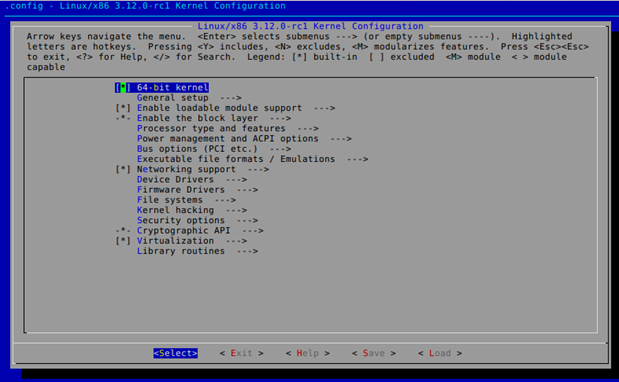
- make xconfig: presents a QT GUI window to give us a chance to configure kernel.
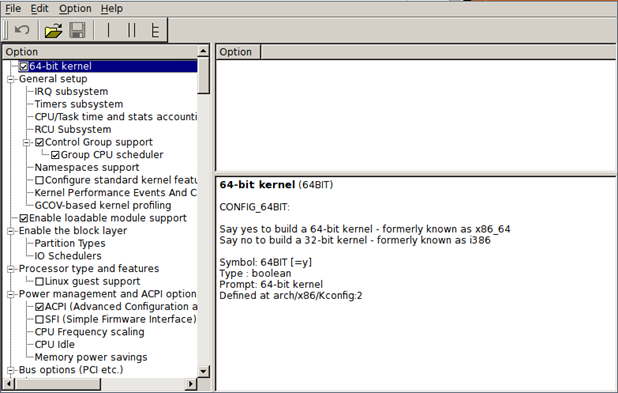
make gconfig: presents a GTK GUI window to give us a change to configure kernel.
After configuring the kernel, a new .config file will be present in the top directory of the kernel source, which will contain all the configuration options in the Linux kernel. After configuring our kernel, we can find a bug we would like to fix.
Finding the Bug
Before we can fix a bug in the Linux kernel, we must first find some interesting bugs. There are number of ways where we can find Linux bugs, some of which are listed below:
- Linux Kernel Bug Tracker [2]
- Linux Kernel Mailing List [3]
- Linux Kernel Subsystem Mailing List
Whenever we find a bug, we should try to reproduce it on the kernel it was reported for and on the latest kernel. But first let's take a look at the Kernel Bugzilla Bug Tracker system at [2]. We need to register a new account and link it to our email address. After account confirmation and authentication, we can click on the "Browse" button on the top of the page to see the bug categories, which can be seen on the picture below.
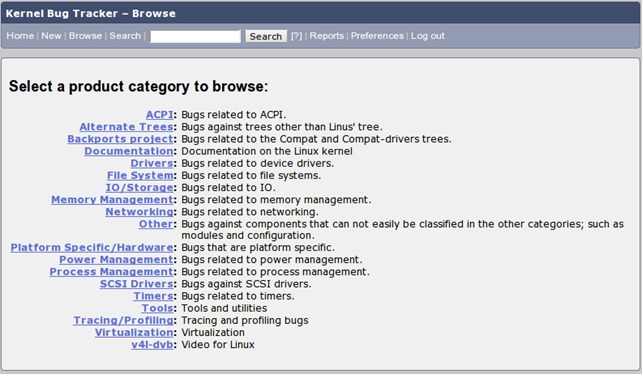
Click on the category that interests you the most and find a bug you would like to help out with. If we're interested in kernel drivers, we might want to click on the Drivers category, which will bring us to another web page presented below (note that all components are not presented for brevity).
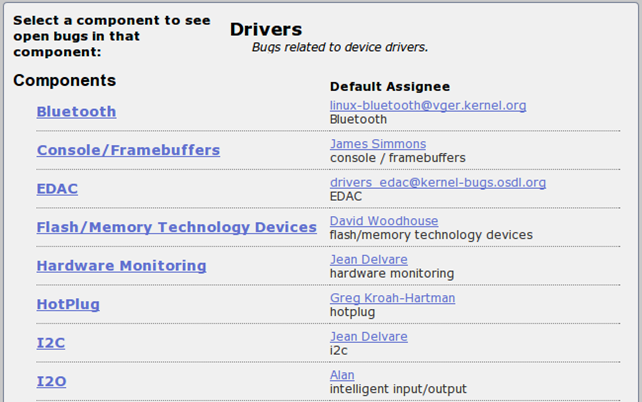
We can see different components inside a category, which we can choose from. On the left there's a list of components, while on the right side we can see default maintainers of the component. If we scroll down the web page, we will see the Network category, which seems interesting. If we click on it, we'll be presented with a list of all the bugs inside the Drivers category and Network component, so we can get a pretty good idea about what kind of bugs to except just from that. A few of the bugs can be seen on the picture below.
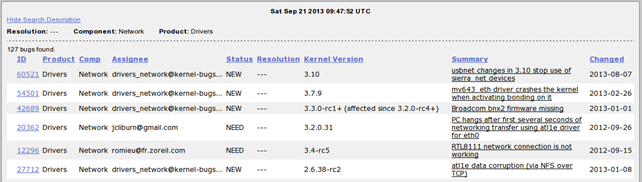
On the picture above there are various columns presenting the bugs
- ID : the sequential ID number of the bug
- Product : the category of the bug
- Comp : the component of the bug
- Assignee : the person to which the bug is assigned
- Status : the status of the bug
- Resolution : whether or not the bug has been resolved
- Kernel Version : the version of the kernel where the bug has been detected
- Summary : a short summary of the bug
- Changed : when has the status of the bug last changed
If we would like to sort the bugs from newest to oldest, we can press the "Changed" column twice to sort them in order.
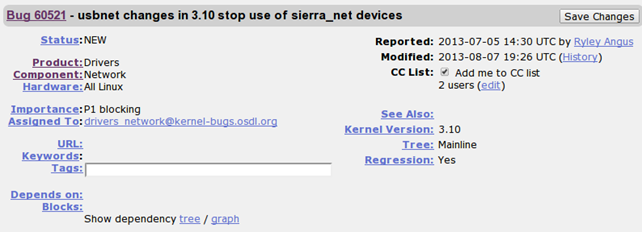
The user can select the bug that is interesting and click on it to find out more about it. The picture below presents the bug 60521. The intriguing part of the bug report is the Hardware element, which specifies that the bug is present for all hardware platforms. We can also see the Reported and Modified dates and times and a CC list; the CC lists contains the users, which should be put in the email CC when sending an update about this bug.
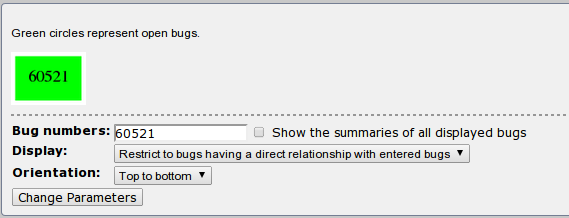
If we click on the "Depends on/Blocks" graph link, we'll be presented with the bug dependency. In our case the bug doesn't have any dependency as can be seen below, but if it did, we would first have to fix the bug the current bug depends upon, before trying to fix this one.
One of the most important information is also the "Kernel Version", which specifies the kernel version where the bug has been observed. If the bug hasn't been fixed, it's probably present in a newer version of the kernel, but that needn't be the case. There are also two attached patches available with this bug and can be seen below.
If we click on the Diff link on the right side of every attached patch, the diff program will be used to compare the previous and patched version of the file and present the result to us.
The diff of the first patch can be seen below:

The diff of the second patch can be seen below:

Notice that the difference is only in the value being used after the comparison operator.
Fixing the Bug
Remember that whatever you change in the Kernel source code, you should be doing it in your own branch; we shouldn't mess with the master branch. Knowledge about the git version control system might come in handy now, which is why I mentioned it in the beginning of this tutorial. If you don't know what a branch is, you should probably grab a git Reference manual and check it out.
Whenever we want to change a file to fix a bug, we should create a new branch and put all the changes there. Branching is useful, because we can easily control the changes we've made to the Linux source tree compared to someone else; if we later realize we messed things up, we can revert the changes very easily. Essentially, we can create a branch and change to the newly created branch with the following commands. The last "git branch" command just prints all the local branches in the current repository and marks the active branch with asterisks (character '*').
[plain]
# git branch mybranch
# git checkout mybranch
# git branch
After that we can fix a bug, which should change the source code. To add it back into the git version control, we need to issue the "git add" command.
[plain]
# git add file.c
After we've made some changes we must test it to make sure that they work. The very first thing is building the changed driver or some other component, which can be done in various ways. If we haven't compiled our kernel in the past, we have to run the command below. The make will build the kernel, while the make modules will build the enabled modules. If we would like to load the built modules into the current running system, we can optionally run the make modules_install command. All the modules will be put into the /lib/modules/<kernel_version>/ directory.
[plain]
# make && make modules && make modules_install
After we've compiled the kernel for the first time, we should compile only part of the kernel where we've made a change. If we have changed a driver in the drivers/ide/ directory, we can only run the command below to build the modules from that directory only rather than whole kernel.
[plain]
# make M=drivers/ide/
After we've built the module, we can insert it into the Linux kernel by using the insmod command:
[plain]
# insmod foobar.ko
Sometimes, we must also boot the new kernel to check that the bug has been fixed. This can be done simply by first copying the new kernel to /boot/ directory. Don't overwrite the old kernel in case something broke in the newly built kernel. You should keep the old kernel intact, so you can boot back into the system if the new kernel is broken; if you've accidently overwritten the old kernel and the new kernel doesn't boot, you'll have to boot up a live-cd and fix the problem there; you'll have considerable problems doing that and you'll get frustrated when something doesn't work. Rather than that, simply keep the old version of the kernel around just in case. Basically all you need to do is copy the bzImage (from arch/x86_64/boot/bzImage to /boot/kernel_new) to /boot partition and change the /boot/grub/grub.conf configuration file to result the newly build kernel. You should have something like the following in your grub.conf:
[plain]
title=kernel_old
root (hd0,0)
title=kerbel_new
root (hd0,0)
kernel /boot/kernel_new root=/dev/sda1
The title is the text that appears when Grub prompt is presented to us when booting an operating system. The root specifies the partition where the primary system is located; in our case it points to the same system, just the kernel is different. The kernel specifies an actual file inside the /boot/ partition where we've copied our kernel. The old kernel is located at /boot/kernel_old, while the new kernel is located at /boot/kernel_new.
After we've verified that the new code compiles and tested our bug fix, either by inserting the compiled module into the current system by using insmod or booted a whole new kernel, we should commit it to the Git repository.
[plain]
# git commit file.c
Every commit needs a message that specifies what has been changed/fixed in the modified file. Usually we want the first line to be a very short description of what we fixed with the commit, while the rest of the message should describe the bug in more detail. At the end of the message there should be the author of the patch as well as the maintainers who marked the patch as being valid; they can be thought as the people who reviewed the change and are presented with the Signed-off-by directive in the git commit message.
Creating the Patch
Once we've verified that we have fixed the bug, we need to create a patch. We can do that by using "git format-patch" command, where we need to make a diff between the master and the mybranch branch. This can be done with the command presented below.
[plain]
# git format-patch master..mybranch
The format-patch will create a .patch file in the current directory and turn into an email, which we need to send. We should also use the checkpatch.pl perl script to check the patch for error messages:
[plain]
# ./scripts/checkpatch.pl fixedbug.patch
We can use various GUI mail clients, but they mostly don't work the way we would like, which is why it's better to use a console based mail client like mutt. But there's also a better solution that we can use, the "git send-email" command. Before doing that we need to determine to whom we would like to send this email. This is why the get_maintainer.pl perl script can be used, which prints the maintainers of the files changed in the patch. The script actually prints the maintainer names as well as their email addresses to the stdout.
[plain]
# ./scripts/get_maintainer.pl fixedbug.patch
After that we can use the "git send-email" to actually send the patch to one or multiple maintainers printed by the get_maintainer.pl script.
[plain]
# git send-email –to <a href="mailto:maintainer@domain.com">maintainer@domain.com</a> –cc <a href="mailto:devel@driverdev.osuosl.org">devel@driverdev.osuosl.org</a> fixedbug.patch
But how does the git know how to send emails; by properly configuring the sendemail configuration option in ~/.gitconfig file. We can configure git to connect to Gmail server and send emails from there or we can use local mail server if we have it installed.
When we stumble upon a driver that doesn't quite work, we have to blame someone for it. Therefore, we can use the "git blame" command to print the authors of every single line in that driver. Once we located the certain commit, we can show the entire commit message by issuing the "git show" command as follows:
[plain]
# git show f31e21ab
Kernel Source Overview
If we issue the ls command under our kernel source, we can see a lot of directories and understanding them might help us in kernel development. This section has been summarized after [4]. The directories are the following:
- Documentation: the kernel documentation, which is kept up-to date.
- arch: architecture specific code.
- block: code for kernel block drivers.
- crypto: crypthographic code use by the kernel.
- drivers: drivers for various devices.
- firmware: contains firmware code for various devices.
- fs: filesystem code.
- include: headers files.
- init: the initialization code.
- ipc: code for interprocess communication.
- kernel: generic kernel code like scheduler.
- lib: generic library that can be used by any kernel code.
- mm: memory-management code, like setting up virtual memory, swapping out pages, etc.
- net: networking code.
- samples: contains various examples.
- scripts: scripts that can be useful when working with kernel code.
- security: Linux security code.
- sound: drivers for sound cards.
- tools: contains various tools.
- usr: contains code that can build a cpio format archive that contains a root filesystem image.
- virt: contains KVM code for virtualization.
Writing a New Module
Here we'll take a look at how we can write a completely new module in Linux kernel. The skeleton of the Linux kernel module can be seen below; copy the program into drivers/misc/skel.c to be able to work with it later on.
[plain]
# cat skel.c
#include <linux/init.h>
static int my_init(void)
{
printk ("The my_init function called!n");
return 0;
static void my_exit(void)
{
printk ("The my_exit function called!n");
return;
module_init(my_init);
module_exit(my_exit);
The skeleton module doesn't do anything except load and unload the module. The module_init function is used to register the initialization function, which is called upon module loading and the module_exit function is used to register the exit function that is called when the module is unloaded. Those two function are declared in the linux/init.h header file, which is why we must include that header file. That file can be located at include/linux/init.h; the copied declarations of module_init and module_exit functions can be seen below:
[plain]
/**
* module_init() - driver initialization entry point
* @x: function to be run at kernel boot time or module insertion
*
* module_init() will either be called during do_initcalls() (if
* builtin) or at module insertion time (if a module). There can only
* be one per module.
*/
/**
* module_exit() - driver exit entry point
* @x: function to be run when driver is removed
*
* module_exit() will wrap the driver clean-up code
* with cleanup_module() when used with rmmod when
* the driver is a module. If the driver is statically
* compiled into the kernel, module_exit() has no effect.
* There can only be one per module.
*/
#define module_exit(x) __exitcall(x);
Let's now display the Makefile in the same directory, which contains the following.
[plain]
#
# Makefile for misc devices that really don't fit anywhere else.
obj-$(CONFIG_IBM_ASM) += ibmasm/
obj-$(CONFIG_AD525X_DPOT) += ad525x_dpot.o
obj-$(CONFIG_AD525X_DPOT_I2C) += ad525x_dpot-i2c.o
obj-$(CONFIG_AD525X_DPOT_SPI) += ad525x_dpot-spi.o
obj-$(CONFIG_INTEL_MID_PTI) += pti.o
obj-$(CONFIG_ATMEL_PWM) += atmel_pwm.o
Notice that every option in the kernel has its own obj-xyz entry, where the xyz most often stands for y (built-in) or m (module). We can print all of the values set in the current kernel by printing the values in the .config file as seen below:
[plain]
# cat .config | sed 's/.*=//g' | grep -v ^# | grep -v ^$ | sort | uniq -c
4 ""
1 "(none)"
1 "-fcall-saved-rdi -fcall-saved-rsi -fcall-saved-rdx -fcall-saved-rcx -fcall-saved-r8 -fcall-saved-r9 -fcall-saved-r10 -fcall-saved-r11"
1 "/lib/firmware/"
1 "/lib/modules/$UNAME_RELEASE/.config"
1 "/sbin/hotplug"
1 "arch/x86/configs/x86_64_defconfig"
1 "cfq"
1 "cubic"
1 "elf64-x86-64"
1 "iso8859-1"
1 "minstrel_ht"
1 "radeon/PALM_pfp.bin radeon/PALM_me.bin radeon/SUMO_rlc.bin"
1 "rtc0"
1 "selinux"
1 "utf8"
6 0
2 0x1000000
1 0xdead000000000000
4 1
1 1000
1 1024
3 16
1 16384
1 18
1 2
1 2048
2 3
4 32
3 4
1 4096
1 437
3 6
1 60
6 64
1 65536
1 768
1 8
78 m
1019 y
The command above takes just the values of all variables set in the .config file, discards the comment and empty lines and counts the number of occurrences of each unique string. The first column in the output presents the number of occurrences of the corresponding string in the second column. The most widely used characters are y (built-in) and m (module). Therefore if we would like to build our module, we have to add an additional line to the Makefile that presents the skel.c as a module.
[plain]
obj-m := skel.o
After that we can rebuild just the drivers/misc/ directory by executing the "make modules" command by adding it a few arguments. The output of the command clearly states that the skel.c file has been built.
[plain]
# make -C /usr/src/linux-latest/ M=`pwd` modules
make: Entering directory `/usr/src/linux-latest'
CC [M] /usr/src/linux-latest/drivers/misc/skel.o
Building modules, stage 2.
MODPOST 2 modules
CC /usr/src/linux-latest/drivers/misc/skel.mod.o
LD [M] /usr/src/linux-latest/drivers/misc/skel.ko
make: Leaving directory `/usr/src/linux-latest'
The module should have the .ko extension, which it indeed has as seen below:
[plain]
# ls skel.*
skel.c skel.ko skel.mod.c skel.mod.o skel.o
If we try to load the module right now with the insmod command, we're receive an error.
[plain]
# insmod skel.ko
insmod: ERROR: could not insert module skel.ko: Invalid module format
We can execute the dmesg command to look at the error message:
[plain]
# dmesg
[32529.042718] skel: version magic '3.12.0-rc1+ SMP preempt mod_unload ' should be '3.4.9 SMP preempt mod_unload'
Notice the error message informing us that we should be inserting the built module into the kernel 3.12.0-rc1 rather than into the 3.4.9 (as is the current kernel version), which you can also display by executing "uname -a". After a reboot, we can verify that we're using the right kernel version:
[plain]
# uname -rv
3.12.0-rc1+ #1 SMP PREEMPT Sat Sep 21 18:36:28 CEST 2013
If we now insert the module into the kernel again, there will be no errors:
[plain]
# insmod skel.ko
We can also check that the module has been successfully loaded with lsmod command:
[plain]
# lsmod
Module Size Used by
skel 938 0
At the end we should also check whether the printk function inside the my_init was successfully called. In the output below, we can see that the message was printed, which means that we've successfully created our first kernel module and loaded it.
[plain]
# dmesg | tail
[ 233.998939] The my_init function called!
Let's also unload the module:
[plain]
# rmmod skel
And check whether the printk of the my_exit function was called:
[plain]
# dmesg | tail
[ 407.818205] The my_exit function called!
Conclusion
In this short article we've seen how we can fix bugs in Linux kernel. At first we need to download the latest version of the kernel source. Then we have to find the bug we're interested in and read its full description, so we can understand it properly. When we decide that this is indeed the bug we want to fix, we have to create a new branch and make our changes there. Once we've verified that the bug has been fixed, we can commit it to the git repository and send email about the patch to the maintainer.
You should also keep in mind that you're operating in kernel-mode, which is quite different from user-mode, which we normally work with. A bug in the kernel-mode can crash the whole system, while a bug in user-mode cannot do that. This is one of the principles of virtual address space, where each process is given 4GB of virtual memory (on 32-bit systems), but it only uses a fraction of that user-space. Therefore a bug in the user-space program can overflow only its own memory and not the memory of another process or worse, the kernel itself. But processes also need a way to trigger advanced operations that cannot be done in user-mode; this is why the processes use system functions to request the kernel-mode to do some actions for them. At the end of the day remember that you're operating in kernel-mode and should be more careful then in user-mode, since your mistake can crash whole system, which is most certainly not what we want to achieve.
References:
[1] Greg Kroah-Hartman, Write and Submit your first Linux Kernel Patch,
https://www.youtube.com/watch?v=LLBrBBImJt4.
[2] Kernel Bug Tracker,
[3] Kernel Mailing List,
http://vger.kernel.org/vger-lists.html#linux-kernel.
[4] Hacking the Linux 2.6 kernel, Part 2: Making your first hack,
Become a certified reverse engineer!
http://www.ibm.com/developerworks/linux/tutorials/l-kernelhack2/section2.html.
- Exam Pass Guarantee
- Live expert instruction
- Hands-on labs
- CREA exam voucher
In this Series
- Linux Kernel Development Process
- Kali Linux: Top 8 tools for reverse engineering
- Stacks and Heap
- Top 8 reverse engineering tools for cyber security professionals [updated 2021]
- Arrays, Structs and Linked Lists
- Reverse engineering obfuscated assemblies [updated 2019]
- Crack Me Challenge Part 4 [Updated 2019]
- Writing windows kernel mode driver [Updated 2019]
- Assembly programming with Visual Studio.NET
- The basics of IDA pro
- Reverse engineering tools
- Hacking tools: Reverse engineering
- Reverse engineering a JavaScript obfuscated dropper
- Reverse Engineering – LAB 3
- Exploiting Protostar – Stack 0-3
- Reversing Binary: Spotting Bug without Source Code
- Reverse engineering virtual machine protected binaries
- Introduction to Reverse Engineering
- Pafish (Paranoid Fish)
- Extending Debuggers
- Encrypted code reverse engineering: Bypassing obfuscation
- Buffer Overflow Attack & Defense
- Invoking Assembly Code in C#
- iOS Application Security Part 32 - Automating tasks with iOS Reverse Engineering Toolkit (iRET)
- Hooking IDT
- A Guide to Debugging Android Binaries
- Kernel debugging with Qemu and WinDbg
- Shared Folders with Samba and Qemu
- Testing Hooks via the Windows Debugger – An Introduction to RevEngX
- Reverse Engineering with Reflector
- Applied Reverse Engineering with IDA Pro
- Injecting spyware in an EXE (code injection)
- Disassembler Mechanized Part 4: DLL Injector Development
- Disassembler Mechanized Part 3: Code Injection Operation
- Debugging TLS callbacks
- Disassembler Mechanized Part 2: Generating C# and MSIL code
- System address map initialization in x86/x64 architecture part 2: PCI express-based systems
- Coding of Disassembler
- Applied cracking & byte patching with IDA Pro
- .NET reversing with Reflexil
- Reversing firmware part 1
- Reverse Engineering with Reflector: Part 1
- Remoting Technology
- Reverse engineering with OllyDbg
- Understanding Session Fixation
- Optimizing Managed Code Execution
- File system manipulation
- The BodgeIt store part two
- The BodgeIt store part one
- Understanding Windows Internal Call Structure
- Pin: Dynamic Binary Instrumentation Framework

Get certified and advance your career
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, (ISC)², Cisco, Microsoft and more!

Reverse engineering
Reverse engineering
Reverse engineering
Top 8 reverse engineering tools for cyber security professionals [updated 2021]
Reverse engineering