A prototype model for web application fingerprinting: w3 scrape

Introduction:
Web application fingerprinting is one of the most important aspects of the information gathering phase of ethical hacking. This allows us to narrow down the criteria instead of playing around with a large pool of possibilities. Fingerprinting simply means identification of objects using a certain methodology. Web application fingerprinting, specifically, is meant for identifying applications running on the HTTP server.
If you're wondering what can be unearthed by web application fingerprinting, be sure that we can find information regarding the web server software hosting the website, its version, and other deployment details as I will show later in this article. This also plays an important role in administering patches for the HTTP-based applications and profiling web servers. It is a well-known fact that almost companies having a web presence has its port 80 open. Web servers with this configuration can reveal very interesting information for the attackers who are on the hunt for such info. This helps the hackers chart an attack plan against the server and ultimately gain root access. In addition, this helps them evade IDS as it is going to be a thoroughly planned attack.
The prototype model described in this article is based on a tool under development. The tool is not only developed to fingerprint the web application, but it's also designed to detect vulnerabilities and suggest patches to fix them.
Current scenario:
In the current market scenario, various such tools exist with their own benefits and limitations, as we will see, one by one. Methods such as HTML data inspection, file and folder presence (using HTTP response codes), and check sum based identification are available. Each method has a dedicated tool with its application. The following are the best tools that do the task of fingerprinting most effectively. The details of each tool are mentioned underneath their name.
WhatWeb:
A ruby based application designed to detect virtually any application, with a pluggable architecture. WhatWeb performs various tasks such as match regex patterns, Google dork checks, file existence checks as well as file content checks through md5 based matching. This varied form of identification allows WhatWeb to report the analysis more accurately.
Plecost:
The basic principle behind Plecost is to find the right set of files. For any particular web application, or a Content Management System, it searches first for a particular type of a file, and then derives the necessary information within the file. For example, readme.html for Wordpress CMS contains the version information, which the tool uses in its analysis. This works well with WordPress because they have a practice that every author must have a well-defined readme.html file for every module written by them.
Wapplyzer:
This tool comes in the form of a Firefox/Chrome plug-in. It waits for the page to be loaded in the browser and then uses regex pattern matches to determine the version and type of the application.
Blind Elephant:
One of the most accurate and dynamic tools in the market, Blind Elephant works on the principles of checksum based version difference. Thus, this tool is more robust and flexible in nature, allowing it to work under both open source and proprietary platforms.
W3-scrape a prototype model in action:
W3 scrape is a reconnaissance based reporting tool focusing on the requirements of a web application tester and trying to incorporate most of the requirements under one roof. The various components of this model are Page Source, IP Harvester, Render Modified Source, Fingerprinting Module, CMS Identification Module, SQL Injection Detection, and a Phishing Detector. It also includes a complete report generator for all these scans.
HTML source view:
This tool comes with a private browser within itself, where you can enter the URL and view the page as well as its html source. This helps in being anonymous with respect to the system where you are using the tool. It functions as a usual browser but the only difference being that, the browser is within the tool.

11 courses, 8+ hours of training
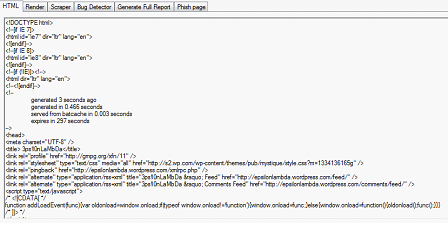
IP Harvesting module:
This module lets you determine the range of IP addresses that a particular domain is using. The tool sends a query to the DNS Records on the internet, then retrieves the information and displays it in the report.
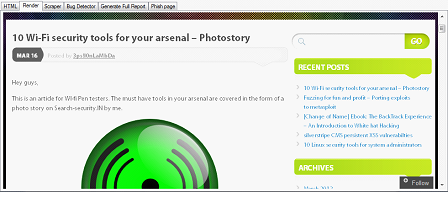
Rendering HTML source:
Suppose you wish to see how a web page looks after custom modification of the source. With this tool, you just need to click on the render button to see the page in its new avatar. This comes particularly handy when the attacker is crafting a phishing attack and testing his web page in order to make it look as genuine as possible.
Fingerprinting module:
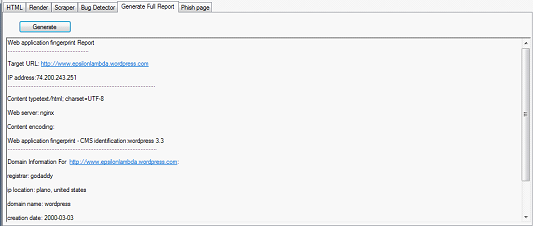
The tool captures the http header based information, and fingerprints the type of the content, server name, server version along with its geo location. This information comes in handy when charting out an attack plan, as we know that vulnerabilities are version specific and vendor specific. The version and vendor of the server application gives a hacker enough clue to kick-start his attack. Another important note is that with this set of information an attacker can host a local environment with similar settings and test for the behavior of the target for a certain amount of time that they might want to try it out.
CMS Identification:
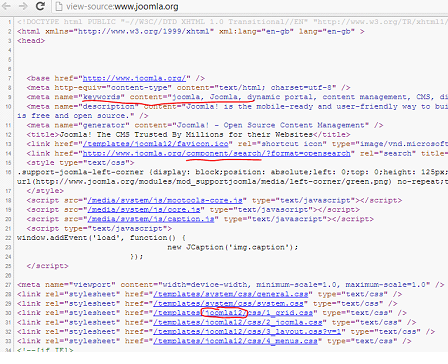
As mentioned above, CMS identification happens in various ways. The most common are HTML data inspections and URL inspections, followed by regex pattern matching and checksum identification. The approach used within here is to download a page from its server and then use regex patterns to retrieve more specific information about the CMS. HTML data inspection can be easily performed manually too. The following figure shows the HTML data inspection. This figure is specifically with respect to Joomla CMS. The highlighted parts of the source are specific to Joomla Implementation, and key in finding the CMS to be of the type Joomla. Similarly, each CMS has its own unique way of representing itself. When the intelligence of the tool combines various factors together before giving out the results, the result will always be more accurate. This is called multi-factored analysis of a given target.
SQL injection detection:
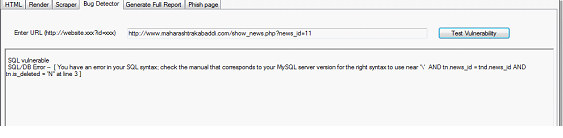
The tool takes the input in a particular format and runs the injecting scripts on the target and looks for the error response from the server. If the tool is successful in triggering an SQL error it reports the vulnerability as shown in the figure.
Phishing detection module:
This module is a new implementation clubbed with this tool. We use various criteria to check if the link is possibly phished or not. It's impossible to be 100 percent that it is or is not a phished page, but it warns if it finds the URL to be sketchy. Various criteria that are checked for determining the phishing potential of a web page include the age of the URL (most newly created pages until they exist on the internet for a threshold amount of time, say 6 – 8 months, may be phished links that are created for that time frame, to attack a particular target). Another measure to be checked here is the presence of URL redirection scripts. Though many sites use redirection as a parameter in their URLs, the tool has to gain intelligence, as to know whether the redirected URL is from the same domain or a different domain. If they are of the same domain, the risk for phishing is low. However, if it turns out to be on a different domain, then on the redirected URL a recursive check has to be made on these various criteria. Few other test cases to be included in the phishing detection module can be usage of dots in the links (basically to check if it's from a valid DNS tree or not). In addition, we can check the presence of IP addresses within the links.


11 courses, 8+ hours of training
This tool uses a Windows API and it is working, as it is evident from the screenshots. The primary advantage is that the novice users who find it uncomfortable to work on the command line based interface of Linux can easily adapt to this tool and get handy experience on the nascent field of web application fingerprinting. The availability of a seamless Graphical User Interface (GUI) makes the user experience much quicker and more effective
The tool that is described in its article can be used by both the white-hat and the black-hat based attackers depending on their motives. The penetration tester can narrow down on large pools of possibilities by running this tool against their target web application. The tool still calls for a lot of refinement, and this is just a Proof of Concept of how a particular tool of this sort could be designed making every resource available using just one software for a security evangelist.
I would be more than happy to see any further refinements and additions to the prototype that I've proposed in this article.

Learn how to secure systems with 11 courses from Infosec Skills instructor and #1 best-selling author Ted Harrington.
- Hack your system
- Establish your threat model
- Spend wisely
- And more
In this Series
- A prototype model for web application fingerprinting: w3 scrape
- DevSecOps: Moving from “shift left” to “born left”
- What’s new in the OWASP Top 10 for 2023?
- DevSecOps: Continuous Integration Continuous Delivery (CI-CD) tools
- Introduction to DevSecOps and its evolution and statistics
- MongoDB (part 3): How to secure data
- MongoDB (part 2): How to manage data using CRUD operations
- MongoDB (part 1): How to design a schemaless, NoSQL database
- Understanding the DevSecOps Pipeline
- API Security: How to take a layered approach to protect your data
- How to find the perfect security partner for your company
- Security gives your company a competitive advantage
- 3 major flaws of the black-box approach to security testing
- Can bug bounty programs replace dedicated security testing?
- The 7 steps of ethical hacking
- Laravel authorization best practices and tips
- Learn how to do application security right in your organization
- How to use authorization in Laravel: Gates, policies, roles and permissions
- Is your company testing security often enough?
- Authentication vs. authorization: Which one should you use, and when?
- Why your company should prioritize security vulnerabilities by severity
- There’s no such thing as “done” with application security
- Understanding hackers: The insider threat
- Understanding hackers: The 5 primary types of external attackers
- Want to improve the security of your application? Think like a hacker
- 5 problems with securing applications
- Why you should build security into your system, rather than bolt it on
- Why a skills shortage is one of the biggest security challenges for companies
- How should your company think about investing in security?
- How to carry out a watering hole attack: Examples and video walkthrough
- How cross-site scripting attacks work: Examples and video walkthrough
- How SQL injection attacks work: Examples and video walkthrough
- Securing the Kubernetes cluster
- How to run a software composition analysis tool
- How to run a SAST (static application security test): tips & tools
- How to run an interactive application security test (IAST): Tips & tools
- How to run a dynamic application security test (DAST): Tips & tools
- Introduction to Kubernetes security
- Key findings from ESG’s Modern Application Development Security report
- Microsoft’s Project OneFuzz Framework with Azure: Overview and concerns
- Software maturity models for AppSec initiatives
- Best free and open source SQL injection tools [updated 2021]
- Pysa 101: Overview of Facebook’s open-source Python code analysis tool
- Improving web application security with purple teams
- Open-source application security flaws: What you should know and how to spot them
- Android app security: Over 12,000 popular Android apps contain undocumented backdoors
- 13 common web app vulnerabilities not included in the OWASP Top 10
- Fuzzing, security testing and tips for a career in AppSec
- 14 best open-source web application vulnerability scanners [updated for 2020]
- 6 ways to address the OWASP top 10 vulnerabilities
- Ways to protect your mobile applications against hacking

Get certified and advance your career
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, (ISC)², Cisco, Microsoft and more!

Application security
Application security
Application security
DevSecOps: Continuous Integration Continuous Delivery (CI-CD) tools
Application security