Memory Models

Memory
We know about user mode and kernel mode, and how programs in user-mode can only use the memory from 0x00000000 to 0x7FFFFFFF, while the system uses the memory from 0x80000000 to 0xFFFFFFFF.

Become a certified reverse engineer!
Let's talk about physical memory for a bit. Each computer must have a memory chip in which each byte has its own physical address that can be used to access that byte. If we look at the hardware RAM chip in the computer, we can see the pins that directly correlate to the physical addresses we're talking about.
Let's look at the SIMM and DIMMs for a moment. SIMM is a single in-line memory module that contains random access memory. This module type was dominant in the years 1980-1990, but was replaced by the DIMM that's used today.
Let's take a look at the picture below, which presents two types of SIMM [1]:

On the picture above, the first module is a 30-bit SIMM and the second one is a 72-pin SIMM. Let's also examine the picture taken from [2], which can be seen below:

On the picture we can see two types of DIMMs: the first is a 168 SDRAM module, while the bottom one is a 184-pin DDR SDRAM module. If we count the number of pins, we can figure out how the two module types are different. The pins on both sides of the SIMM module are redundant, while the DIMM module uses the pins on both sides. The DIMM has twice as many pins as can be seen on the picture above, because we need to count them twice. Also, the SIMMs have a 32-bit data path, while the DIMMs have a 64-bit data path, thus the bus width is 64-bits wide [2].
When talking about rootkits, we must be aware of pretty much every little thing needed to actually run the system, including the hardware components. The IA-32 processors use 32-bits for addressing the memory value. There are various buses in the computer hardware system which are described below. Let's first take a look at the picture below that was taken from [3]:
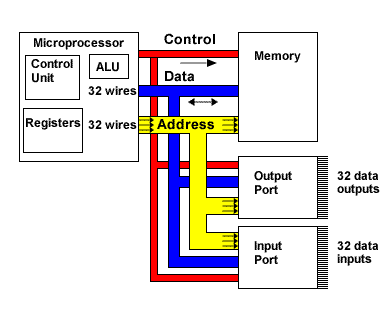
Here we can see the control, data and address bus being used to connect various components together to make a whole system. The address bus is being used to determine the location in memory that the processor will read data from or write data to. The data bus is used to transfer the data from/to memory. The control bus is used to control all the operations taking place: it specifies whether we're currently processing a read or write operation, and also ensures that the operation takes place at the right time [3].
Whenever we're reading or writing data from/to memory, all three of the buses are used to perform the operation. The address bus holds the address from which we would like to read the byte or to which we would like to write the byte, while the read or write signal is sent over the control bus. Then, the data bus is used to send or receive the bytes. Usually, we're not reading or writing one byte at a time, because that would be a waste. The buses are 32-bits wide on the IA-32 systems, which enables us to send 4 bytes at a time on the data byte. This means that we're actually specifying that some address and 4 consecutive memory values will be read and returned to the processor.
But does that mean that on IA-32 processors we can only address 4GB of memory at a time? Yes and no. This assumption is correct, but later, the need arose for more memory to be addressed even by 32-bit systems. This is why the PAE (Physical Address Extension) was introduced, which enables us to address more than 4GB of memory in the 32-bit system. When PAE support is enabled, the system can address 36-bits of physical memory or 64GB. But in the operating system itself, the virtual addresses are still 32-bits, so every process can use at most 4GB of memory at a time.
Notice that, on the picture above, all the three buses are connected to the memory at once? This is possible because the DIMMs today have a greater number of pins that can be used to transfer bytes to the memory.
Accessing Physical Memory
So far we've described the basics of physical memory, presented the SIMM and DIMM, and determined that the IA-32 processor can address at most 64 GB of memory (but if PAE is disabled, only 4GB of memory can be accessed by the system).
We have talked about the physical memory, or RAM chip if you will, that is a piece of hardware we must put into our motherboard and is connected to the CPU by buses. In IA-32 the buses are 32-bits wide and can therefore transfer 4 bytes at a time. The CPU must generate the address and put it on the address bus if it wants to read 4 bytes from that address.
In this subsection, we'll talk about how the processor can address that memory address to access the needed value. There are different solutions that exist and are presented below:
- Flat Memory Model / Linear Memory Model: A model where the CPU can directly address the memory locations that are numbered from 0 – 2^32 (this is usually the case on IA-32 processors). This memory model provides direct access to the physical memory, but virtual memory can still be implemented on top of it.
- Paged Memory Model: When using this model, the physical memory is divided on page frames, while the virtual address space contains pages. The programs know only about the virtual addresses. When we try to access the pages that are not in the physical memory, a page fault is triggered and must be handled by the operating system. Once that happens, the operation system must reserve an empty page frame in the physical memory where the data will be stored to. Also, the page table must be updated to link the certain page from virtual memory to its corresponding page frame in physical memory.
- Segmented Memory Model: With segmented memory model, the physical memory is divided between segments. When we're trying to address a certain memory location, we need to provide the segment ID and the offset within that segment. Each segment has a length associated with it, so we're only allowed to reference the memory locations within that length of the segment. If we try to address a memory location outside of the segment, a segmentation fault is raised [4]. The MMU unit is used to translate the segment and offset within that segment into the memory address.Each program usually uses the code segment where the code instructions are stored; the code segment that the program uses is stored in the CS register. The DS register is used for data segment and specifies the data segment the program is using. The SS register specifies the stack segment of the program. But there's also an extra segment ES which is used for data.Many of the 32-bit operating systems use a segmentation model that simulates the flat memory model by setting the segment base to 0 and length to 2^32. This is done because we don't like to think about that when programming; we only wish to use the virtual address so there is no distinction between the code and data space and we also don't like to think in terms of virtual and physical addresses. The programs can them think in terms like each of them has access to its own 0-2^32 address space, which greatly simplifies the understanding we need to have in order to use such memory locations. Since the program is run in its own memory space, we don't have to worry about accessing memory with relative addressing.
The real difference between the paging and segmentation is not just the division of memory space, but also its visibility to user processes when segmentation is used. This means that the memory will not look like a single large memory, but as a multiple part memory. It's often the case that segmentation is used together with paging, so each process has a number of pages, which in turn contain different segments.
However, we must differentiate between the physical and virtual memory addresses. The above memory models are used by the operating system to manage the physical memory, so don't mix it with the virtual addresses the processes are using.
The operating system uses virtual memory, which is given to the processes. The virtual memory is implemented as a flat memory model, where each process is given a separate chunk of virtual memory of 4GB in size. This makes the distinction between the virtual and physical memory rather big, but all of this is done so that the programmers don't have to worry about how the memory is being used. Because each process has its own 2^32 address space, each process can address any virtual address (this is what the programmer sees) and the operating system takes care of everything else.
When we think about this, we can conclude that virtual address space is just an abstraction above the physical address space, which is quite useful to simplify the process of using memory. But there's another important reason for this: with virtual addresses, memory protection mechanisms can be applied easily, which makes the system more fault tolerant. If the programmer interacts with memory in ways he shouldn't have, only that process will crash. It used to be the case that if a program tries to do something stupid with memory, the whole system would crash.
This isn't the case nowadays. Remember all the times the program you've just been testing gave you a segmentation fault? What happened then? Nothing; the program crashed, we can observe the crash dump, but the system is still running flawlessly. I'm not trying to say that virtual memory is the only one that provides this awesome memory protection handling, but it's certainly one of the more important reasons.
Conclusion
We've seen that operating systems use virtual addresses to access particular memory locations in the main memory of the computer. Since the physical memory is byte addressable, every single byte of memory can be addressed. We've also looked at different techniques at how those bytes can be addressed.
Remember that the operating systems in use today mostly use one of the memory models presented above for handling the physical memory space, while virtual memory is given to each process to make it think that it has 4GB of memory to use; thus, the virtual memory uses a flat memory model. But this isn't the whole story.
Besides the virtual address space the programs use, there are also segment registers that are in use; more specifically, CS (code segment), DS (data segment), SS (stack segments) and others are used by programs. Each of those segment registers contain a segment identifier that points to the GDT (Global Descriptor Table) where the descriptors are stored. So basically, each segment register is a pointer to the segment descriptor in the GDT.
References:
[1]: SIMM, accessible at http://en.wikipedia.org/wiki/SIMM.
[2]: DIMM, accessible at http://en.wikipedia.org/wiki/Dual_in-line_memory_module.
[3] Microprocessor and Memory Basics, accessible at http://www-mdp.eng.cam.ac.uk/web/library/enginfo/mdp_micro/lecture1/lecture1-3-1.html.

[4]: Segmentation, accessible at http://en.wikipedia.org/wiki/Memory_segmentation.
- Exam Pass Guarantee
- Live expert instruction
- Hands-on labs
- CREA exam voucher
In this Series
- Memory Models
- Kali Linux: Top 8 tools for reverse engineering
- Stacks and Heap
- Top 8 reverse engineering tools for cyber security professionals [updated 2021]
- Arrays, Structs and Linked Lists
- Reverse engineering obfuscated assemblies [updated 2019]
- Crack Me Challenge Part 4 [Updated 2019]
- Writing windows kernel mode driver [Updated 2019]
- Assembly programming with Visual Studio.NET
- The basics of IDA pro
- Reverse engineering tools
- Hacking tools: Reverse engineering
- Reverse engineering a JavaScript obfuscated dropper
- Reverse Engineering – LAB 3
- Exploiting Protostar – Stack 0-3
- Reversing Binary: Spotting Bug without Source Code
- Reverse engineering virtual machine protected binaries
- Introduction to Reverse Engineering
- Pafish (Paranoid Fish)
- Extending Debuggers
- Encrypted code reverse engineering: Bypassing obfuscation
- Buffer Overflow Attack & Defense
- Invoking Assembly Code in C#
- iOS Application Security Part 32 - Automating tasks with iOS Reverse Engineering Toolkit (iRET)
- Hooking IDT
- A Guide to Debugging Android Binaries
- Kernel debugging with Qemu and WinDbg
- Shared Folders with Samba and Qemu
- Testing Hooks via the Windows Debugger – An Introduction to RevEngX
- Reverse Engineering with Reflector
- Applied Reverse Engineering with IDA Pro
- Injecting spyware in an EXE (code injection)
- Disassembler Mechanized Part 4: DLL Injector Development
- Disassembler Mechanized Part 3: Code Injection Operation
- Debugging TLS callbacks
- Disassembler Mechanized Part 2: Generating C# and MSIL code
- System address map initialization in x86/x64 architecture part 2: PCI express-based systems
- Coding of Disassembler
- Applied cracking & byte patching with IDA Pro
- .NET reversing with Reflexil
- Reversing firmware part 1
- Reverse Engineering with Reflector: Part 1
- Remoting Technology
- Reverse engineering with OllyDbg
- Understanding Session Fixation
- Optimizing Managed Code Execution
- File system manipulation
- The BodgeIt store part two
- The BodgeIt store part one
- Understanding Windows Internal Call Structure
- Pin: Dynamic Binary Instrumentation Framework

Get certified and advance your career
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, (ISC)², Cisco, Microsoft and more!

Reverse engineering
Reverse engineering
Reverse engineering
Top 8 reverse engineering tools for cyber security professionals [updated 2021]
Reverse engineering