Conditional Complexity of Risk Models

Introduction
"Conditional complexity" (also called cyclomatic complexity) is a term used to measure the complexity of software. The term refers to the number of possible paths through a program function; a higher value means higher maintenance and testing costs. Borrowing that concept in risk modeling, we can apply conditional complexity when calculating the risk severity of security vulnerabilities by evaluating the preconditions necessary for a vulnerability to be exploited.
Example
When doing a security assessment recently, I came across an ugly vulnerability. An attacker who exploited this vulnerability would be able to hijack a victim's session and impersonate that victim on the system. That sort of thing is generally undesirable. Business owners typically don't want something like that to happen, so a knee-jerk reaction is to fix this issue immediately and at all costs. But when is it time to sound the alarm?
The thing is, this particular problem really wasn't that bad. Sure, the impact to the business would certainly be bad, but it likely wouldn't happen. To understand why the sky wasn't falling, let's take a step back and look at what risk and risk management are.
Brief Background on Risk Management
NIST's definition of risk is "a measure of the extent to which an entity is threatened by a potential circumstance or event, and typically a function of: (i) the adverse impacts that would arise if the circumstance or event occurs; and (ii) the likelihood of occurrence."[1] In other words, risk is the measure of something undesirable occurring. One model for calculating risk is:
risk = impact x likelihood
The simplicity of the equation is somewhat deceiving, because impact and likelihood really comprise many other considerations.
Impact, in basic terms, is the amount of damage to an organization caused by the compromise of an asset. Typical considerations that contribute to the impact are based on the data classification of the asset: Is the asset confidential? Proprietary? Public? Compliance can be a primary factor if the asset is governed by legislative regulation (U.S. state privacy laws, HIPPA, SOX, etc.) or industry compliance (PCI).
It is necessary, and is often overlooked, to understand the value of an asset not only as it applies to the organization, but also as it applies to an outsider (e.g., hacker, competitor, or foreign government). For example, an asset that has a "medium" value to an organization might be highly coveted by a competitor, which contributes to an elevated effect on the overall impact should the asset be compromised. In 2002, Princeton admissions officers gained access to Yale's student admissions data.[2] This student admissions list is obviously a valuable asset to Yale, but it's just as--if not more--valuable to Princeton admissions officers for focusing recruiting efforts on students not already committed to other schools.
Often, though, the impact can't be easily measured. An attack that brings down an e-commerce site can be quantitatively measured by the loss of orders. But how much does brand damage cost? Accurately calculating brand damage is difficult and potentially impossible to do in any meaningful way.
Likelihood, the other primary risk factor, comprises characteristics such as sophistication complexity (Does the attacker need special tools or knowledge?), access complexity (Does a user need to be first authenticated and authorized?), and discoverability (Is the vulnerability publicly known?). Like assessing impact, the likelihood is more qualitative than quantitative and is generally done on a relative scale.[3]
Calculating the risk impact and likelihood is key to managing that risk. In economic terms, risk management is a cost justification for securing an asset. This means that when a vulnerability is identified, the organization (the business stakeholders) must determine how to address the risk:
- Remove the risk - eliminate the asset or access to it
- Reduce the risk - add security controls that minimize access to the asset
- Transfer the risk - outsource the control of the asset or purchase insurance
- Accept the risk - do nothing (cross your fingers and hope nothing happens)
The approach to addressing risk is typically a cost/benefit decision (it's called "gambling" in Vegas). Choosing any one of the above risk mitigation approaches has a cost associated with it, and that cost should not exceed the value of the asset. As security practitioners, we must realize that the results of our risk assessments can have a material impact on business decisions and budgets, because decisions are generally based on the risk severity of the findings.
Cyclomatic Complexity
The vulnerability I discussed at the top of this article has a high "conditional complexity," in that it can only be exploited 1) if an attacker is on the same network as the victim at the same time, 2) if the victim accesses the application over an insecure communication channel (non-SSL), and 3) if the application does not require mandatory re-authentication.
That's a lot of "if's." Though the vulnerability itself might sound dangerous in isolation, the number of if's--or conditions--reduces the potential likelihood of exploitation. Updating the risk equation from above, the likelihood decreases as the number of conditions necessary for exploitation increases, decreasing the overall risk:
risk = impact x (likelihood / conditions)
In programming, the term cyclomatic complexity (more accurately referred to here as conditional complexity) refers to the number of discrete paths through a procedure; a higher number of "if" conditions contributes to a higher cyclomatic complexity value. This complexity value is a measure of how maintainable and testable the code is. For example, I'll use this piece of shameful pseudocode that I'm certain I wrote at some point in my life: "Do this if that occurs but not this and only under that condition but only when this other thing isn't true and that other thing hasn't happened yet." That kind of procedure isn't very maintainable, because any small change to the logic could easily break the whole thing. (Indeed, this is the type of code that no one wants to touch. Sometimes just looking at it will break it.) And testing it is another challenge entirely.
The cyclomatic complexity is represented by:
M = E - N + P
where:
E = the number of edges (connections) in the graph
N = the number of nodes in the graph
P = the number of connected components (think of an entry/exit closed loop)
For example:

Fig. 1: Cyclomatic Complexity
In the above graph,
E = 12
N = 9
P = 1 (there is an implied, or virtual, connection between the exit node and the entry node)
so:
M = 12 – 9 + 1
M = 4
A complexity value less than 10 is generally desirable; otherwise, overly complex modules are "more prone to error, are harder to understand, are harder to test, and are harder to modify."[4]
Conditional Complexity Equation
The vulnerability preconditions that I mentioned earlier are like the inverse of these coding conditions. Not only does each condition reduce the likelihood of the vulnerability [4], but each one also reduces the business case for fixing it. It's difficult to justify the business case to spend three man-days to fix a vulnerability that won't likely happen. To a stakeholder, those are three lost days not adding business functionality. The prudence of that decision is obviously based on several factors, but ultimately, a stakeholder must perform the risk management calculus that is appropriate to the organization. When the risk severity ratings are presented to the business stakeholders, these ratings will help inform the business case for their remediation, so proper context must be understood when making this evaluation.
Just as we can calculate the cyclomatic complexity of a software function, we can calculate the conditional complexity of a vulnerability:

L(V) is the likelihood value of a vulnerability, and M is the product of the weighted likelihood of all the preconditions (including the vulnerability itself) necessary to exploit a given vulnerability. In the following graph, there are two preconditions necessary to exploit vulnerability #3:
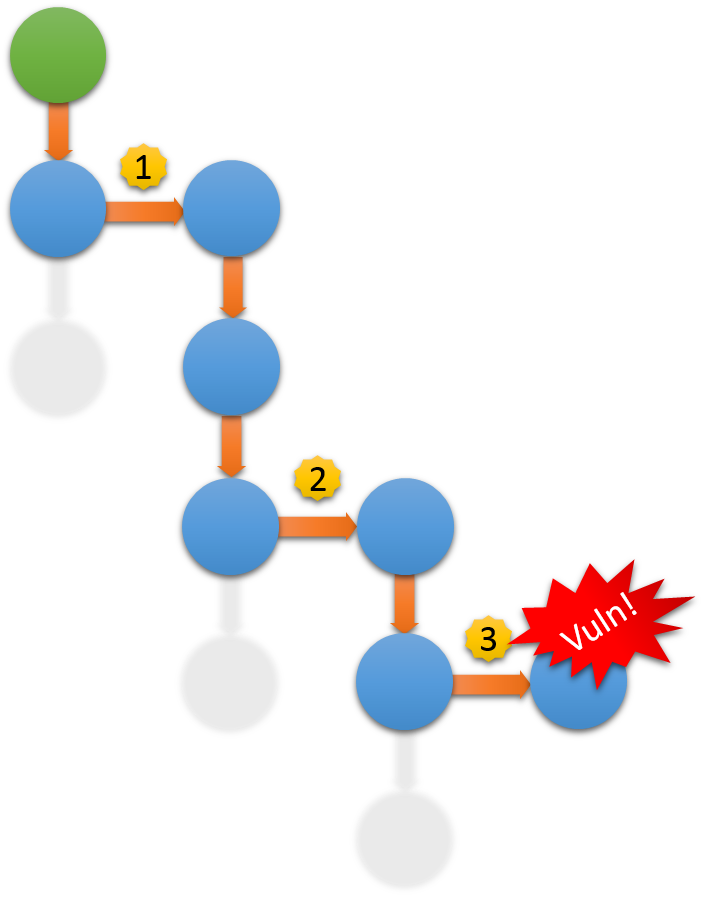
Fig. 2: Conditional Complexity
Let's say the following are the likelihood values for the preconditions (and the target vulnerability itself) on a relative scale of 1 to 5, where 5 is the highest:

Substituting the values, we get:

So the likelihood value of vulnerability #3 in isolation is 4 (out of 5), but in order to exploit it, the chained conditional likelihood value is only 1.
Chaining Vulnerabilities
Most vulnerabilities don't live in isolation, and attackers are generally crafty enough to chain together multiple vulnerabilities or use one vulnerability to pivot to a different vulnerability. If, for example, an attacker were to meet all the preconditions above and actually exploit the vulnerability, then we would have lost the risk management gamble if we hadn't fixed the issue when we found it. These pivot points are called second order vulnerabilities, because even though a single vulnerability might not compromise an asset, it might be necessary to exploit that vulnerability to dive further into the system. A cross-site scripting vulnerability is a good example of this if it is used to acquire a victim's session ID that is then used to infiltrate the system. The cross-site scripting vulnerability itself isn't the culprit, but it is used to exploit a session management vulnerability.
The Unknown Precondition
Calculating the conditional complexity might seem neat and tidy in mathematical terms, but it's the "unknown precondition" that could potentially wreck the whole calculation. So far, I've avoided mentioning the obvious: the conditional complexity equation contains an implied tautological variable that assumes that the vulnerability will be exploited at some point, regardless of the number or likelihood of preconditions. This is the reality of it. But it doesn't make much sense to use that as a business case to justify fixing every vulnerability. While remaining ever vigilant of the unknown precondition, we must take a risk-based approach when presenting the risk severity to the business stakeholders and allow them make informed, risk-based decisions.
Anyone familiar with how Anonymous hacked HBGary Federal saw this in action: SQL injection + poor cryptography + password reuse + social engineering = system takedown. That's a lot of if's, but the product of those preconditions brought down HBGary Federal. However, looking at the vulnerability chain, we could weigh the SQL injection vulnerability relatively high, which would necessarily elevate the product of the other vulnerabilities further down the chain, which would in turn justify the business case for fixing it.
Conclusion
In building software, there is a lot that can go wrong. Fortunately, there are metrics available to help us measure various aspects of the software quality. If we apply the same principle to risk modeling, we can better convey risk to business stakeholders so they can dutifully make decisions based on risk factors that make the most sense to them and the organization. That shouldn't be too big of an "if."
References:
[1] http://csrc.nist.gov/publications/nistpubs/800-30-rev1/sp800_30_r1.pdf
[2] http://www.thecrimson.com/article/2002/8/2/princeton-admits-to-accessing-yale-admissions/
[3] http://www.first.org/cvss/cvss-guide
[4] http://www.mccabe.com/pdf/mccabe-nist235r.pdf
Other resources:
https://www.owasp.org/index.php/OWASP_Risk_Rating_Methodology
http://arstechnica.com/tech-policy/2011/02/anonymous-speaks-the-inside-story-of-the-hbgary-hack/1/
http://www.kb.cert.org/vuls/html/fieldhelp (Note that the CERT scoring system includes precondition as a characteristic of impact instead of likelihood.)

Management, compliance & auditing
Management, compliance & auditing
The top security architect interview questions you need to know
Management, compliance & auditing
Management, compliance & auditing