Fuzzing – Application and File Fuzzing

In our first article, we reviewed the basics of fuzzing as well as the mutation and generation technique. We have also introduced the PeachFuzzer, which we will take a closer look at with this article.
Application Fuzzing:
Whether the application be a desktop app or a web app, there are any number of entry points for fuzzing. In the case if a web application, it can be URL; Query parameters; forms; buttons, and so forth. For a desktop, consider the command line arguments, user interface and onward down the line.

Application Fuzzing with OWASP WebGoat and Burp Suite
WebGoat is a deliberately insecure J2EE web application maintained by OWASP, and designed to teach web application security lessons. WebGoat zipped installation comes with integrated tomcat server, java and WebGoat files. Just keep it running on your localhost machine or some other server.
Burp Suite:
Burp Suite is an integrated platform for attacking web applications. It contains the entire Burp tools with numerous interfaces between them, designed to facilitate and speed up the process of attacking an application. It has an HTTP/S proxy server, which sits in between web browser and web server; a Burp Scanner which performs automated scanning of security vulnerabilities, and a Burp Intruder to automate customised attacks against web applications.
Let's consider an example of Web App fuzzing with a Burp Suite Intruder and an OWASP WebGoat application. The target here is to log into the app as Admin user without the password.
Screen 1: OWASP WebGoat SQL Injection Lab Page. Here we will enter any random "test" password and click on "Login" button. Burp Suite is configured as the proxy server in the background.
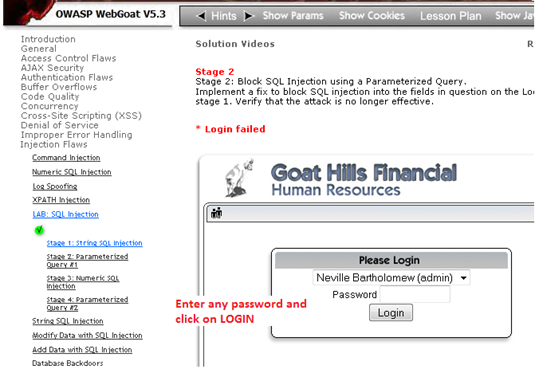
Screen 2: Here's the Burp Proxy page with Intercept "ON." The request which was sent via OWASP WebGoat page is captured on the burp proxy. (We can see the request in the "Intercept" tab.) To modify/fuzz the parameters, here password, we will send the request to BURP Intruder.
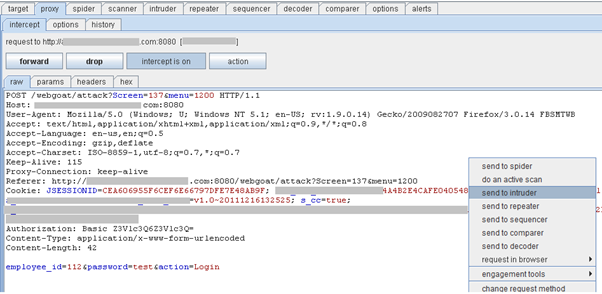
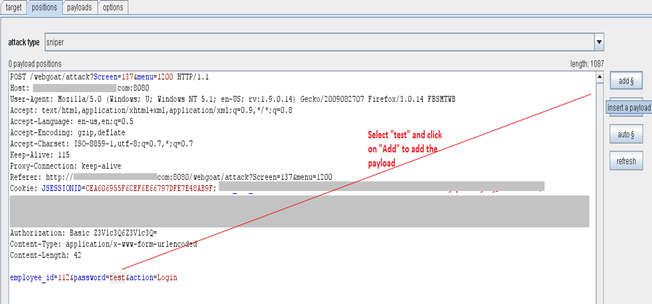
Screen 3: By default, Burp Intruder makes a best guess at where you would place the payloads. It positions these at the value of each URL and body parameter, and each cookie. Here, our target is to position the payload at the password parameter. So we will clear the existing payload and add a new one only at the password parameter.
On our screen, we can also see the dropdown, "Attack type." Burp Intruder supports multiple attack types such as Sniper, battering ram, pitchfork and cluster bomb. These attack types basically define the way in which specified payloads are placed into position. Since we are dealing only with a single payload, we will move ahead with the default option of "sniper".
Screen 4: Now, in the payload tab of the burp intruder, we have option of selecting the payload set and payload processing rules. For our test case, we will select "Fuzzing – SQL Injection" and launch the attack by selecting "Start Attack " from the intruder menu.
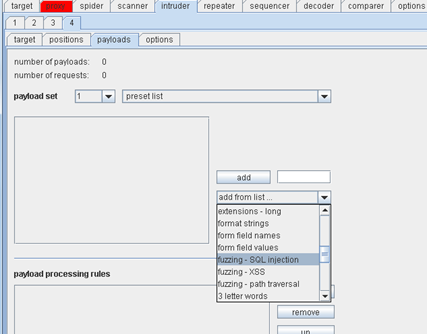
Screen 5:
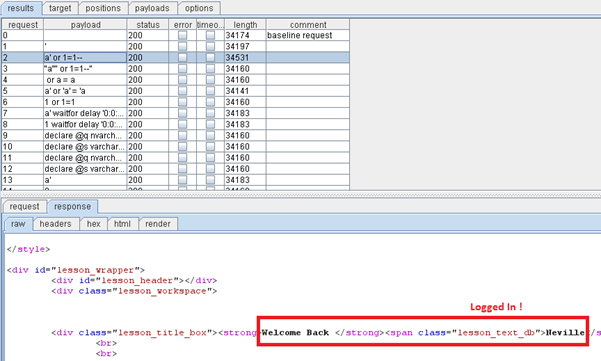
After the fuzzing is complete, we will analyse the requests made by the intruder in the results tab. Sometimes, just checking the length of the response reveals great details. Here , if you see the response of the third request, the page says " Welcome back, Neville," which confirms that using a' or 1=1 – as payload, we can login to the application.
File Format Fuzzing:
In the case of file format fuzzing, a Fuzzer can attack either the deep internals of the application or the structure, file format conventions, and so on. Here, the Fuzzer mainly generates multiple malformed input samples into the application. A crash of the application might need further investigation.
File Format Fuzzing with FuzzWare :
This is a generic fuzzing framework for automatic creation of test cases. It works on the simple protocol: "If you can fuzz XML, then you can fuzz anything that can be described in XML." It can fuzz file formats, network packets (including those saved in PDML format from Wireshark), Web Services (given a WSDL file) and ActiveX controls.
In our example, we will consider a simple case of fuzzing an XML file format. To run this example, we will need sample XML and XSD files. Consider the given files:
Test.xml
[sourcecode lang="xml"]
ABC
1234
XYZ
5678
[/sourcecode]
Test.xsd
[sourcecode]
<!--?xml version="1.0" encoding="utf-8"?-->
[/sourcecode]
Screen 1:
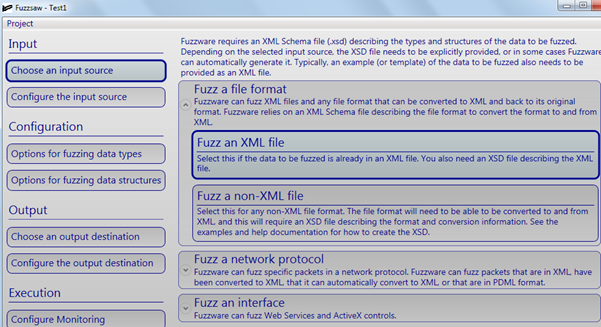
Our first step is to define the input source of the project. Here, we will select "Fuzz an XML fie." For other formats like PDF, JPG, etc., please select "Fuzz a non-XML file".
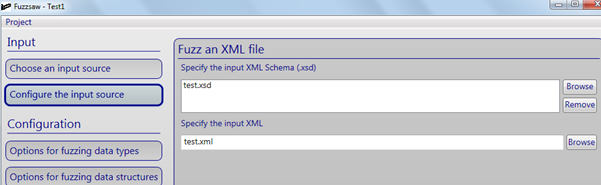
Screen 2: Next step is to configure the input source by selecting the XML Schemas file and the XML file itself.
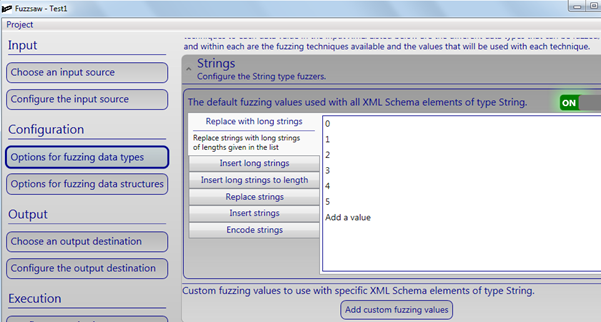
Screen 3: Now, we need to select the fuzzing data type / fuzzing technique. In our case, the XML file contains String as well as Number data types, so we will configure both types of data here .
Screen 4: Next is "Configure and Run Fuzzer." Here, we can start it in test mode to see if all the configurations and data are working fine.
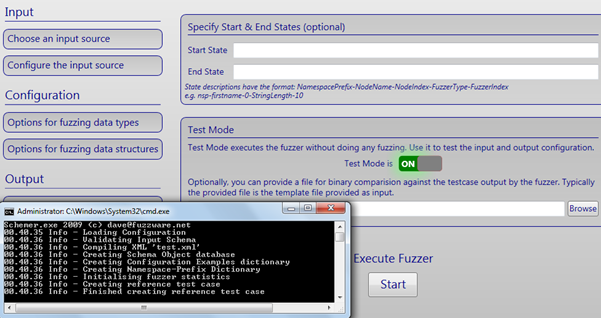
Screen 5: Now, we will switch off the test mode and run the fuzzer.
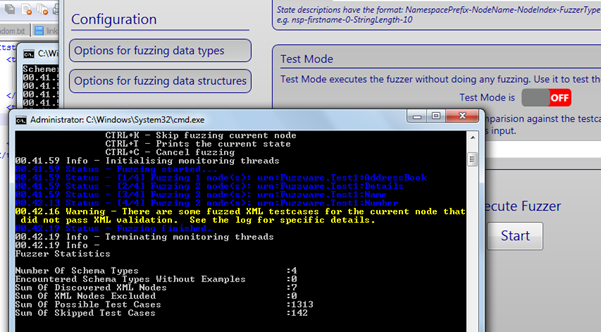
The test cases will be generated in the "output" folder as specified. Sample out test case:
[sourcecode]
AB=C
1234
XYZ
5678
[/sourcecode]
Attack Types/Fuzz Vectors
From all of the above examples, we notice that the common approach to fuzzing is to have list of dangerous values and to use this according to the input to be fuzzed or attack to be run.
Consider this categorization of input data:
Numbers/Integers: Very big numbers; if only integers, then negative numbers and zero
Character/String: Quotes and other special characters, interpretable characters, escaping of characters
Below are the real fuzzing vector examples:
FUZZ * 20FUZZ * 200FUZZ * 2000
%%200d
IMG SRC=javascript:alert('XSS')>
>">script type="text/javascript"//
alert("XSS")
// &
Fuzzing Frameworks and Step by step to Fuzzing
Till now, we have seen multiple fuzzers and fuzzing frameworks. Some of these fuzzing frameworks were developed in C, some in Python and some in Ruby, but a good fuzzing framework is the one which minimizes the number of tedious tasks. The question which arises is how we select which framework to use; the first step for that would be drawing a basic understanding of the functioning of Fuzzers.
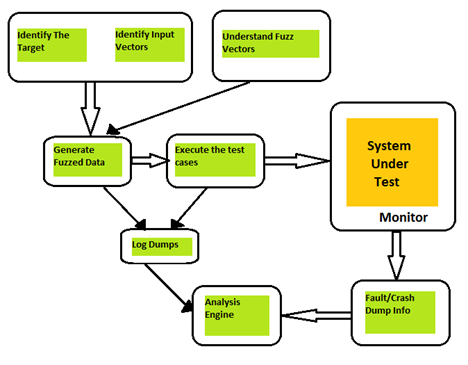
The basic steps in understanding any Fuzzer are:
-
Identify target
Identifying the target to test is definitely the first step to select the fuzzing framework. The target can be a network service, web service, web application, some third party application, and so on.
-
Identify Input Vectors
What comes to your mind when you first think of the inputs in an application might be form data or command line arguments. But they are not the only source of input; we can instead have input from cookies, data files, env variables etc.
-
Understanding the Fuzz Vectors
Before going into the actual fuzzer detail, we need to understand the fuzz vectors (explained above), since these would play an important role in building the framework.
-
Generate the fuzzed data
Now the main component of the framework, "fuzzer," comes into picture, which will generate the fuzzed test cases.
-
Send the fuzzed data
Some fuzzing frameworks save the fuzzed test cases and let you do the rest; while others send this data to the target.
-
Monitor
There is an important monitoring process here in terms of fuzzing a framework. This saves the fault information and, crash information to the disk.
-
Analysis
The information is saved by the monitor process, then analysed further to uncover the real issues.
The above explanation lays down multiple components for any fuzzing framework. We have already come across most of them during our previous examples. To clarify the analogy (as stated in the previous article), we will consider PeachFuzzer as an example, discussed in the first part of this two part series.
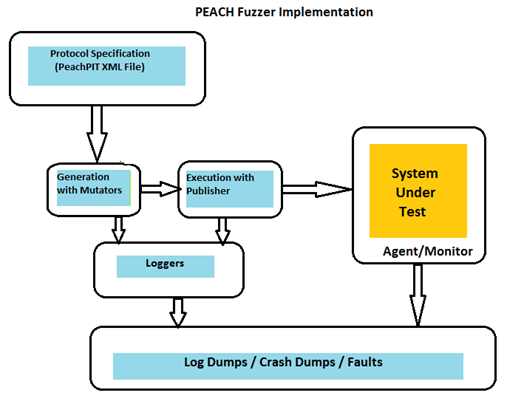
- Generation of fuzzed test cases:
To generate the test case, we will need to understand the protocol/file format (required for intelligent fuzzing), then modify/generate the fuzzed data.
PeachFuzzer has its way of understanding the whole protocol format with its PeachPIT XML file definition. It fuzzes the data with the help of its different mutators which implements a method of mutating data/state. PeachPIT file creation has been explained in the first part of this series in detail.
- Sending the fuzzed test cases:
Now, we need to execute the generated test cases (or in other words, send these test cases to the target). Peach Fuzzer achieves the same result with the help of the different Publisher that it provides.
As said in Peach Fuzzer documentation, Publisher connects the state model actions like "input" and "output" to the actual IO operations such as TCP, Files etc. We will consider two Publishers: file.FilePerIteration and tcp.Tcp.
file.FilePerIteration :
Here our test has publisher "FilePerIteration" as defined below:
[sourcecode]
[/sourcecode]
Now, when we run the PeachPIT file, there will be testcase folder created with all the possible fuzzed test case saved in that folder.
Let's run it with the command: peach HTTP.xml
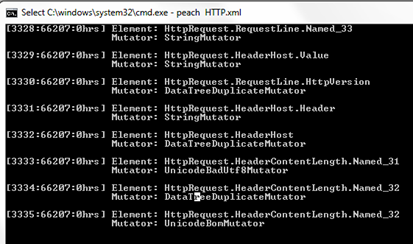
We can see a total of 66207 test cases getting generated, each using different mutators. After this is completed, let's check the testcase folder under the peach directory:-
Let's open any one of the files and see the fuzzed test case generated:
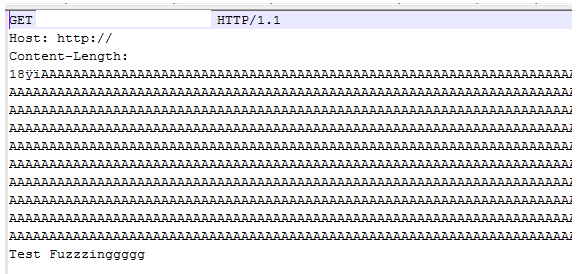
Similarly, let's run the peach fuzzer with the publisher tcp.Tcp as defined below:-
[sourcecode]
[/sourcecode]
Now, to confirm that test cases were targeted to the web server, let's check the log of web server .
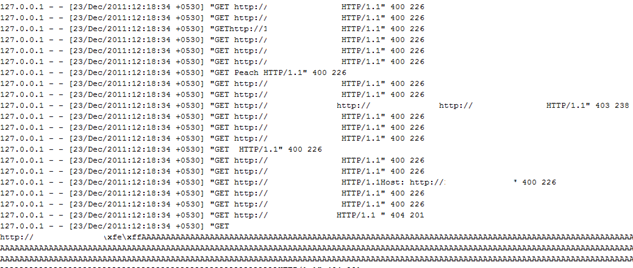
- Monitor
For monitoring purposes, Peach has two components: Agent and Monitor. Agents are special Peach processes that can be run locally or remotely. These processes host one or more monitors that can perform actions such as attaching debuggers, watching memory consumption, capturing network traffic, and so on.
We will consider PCapMonitor as an example. It's is used to capture network traffic during test iteration and send back a pcap capture file if any fault is detected.
[sourcecode]
[/sourcecode]
Now include the Agent in the test which we had created:
[sourcecode]
[/sourcecode]
Now run the Peach fuzzer as usual and you can see Peach Agent window started to capture the faults:
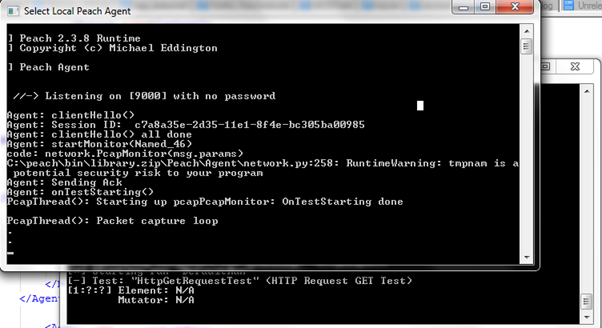
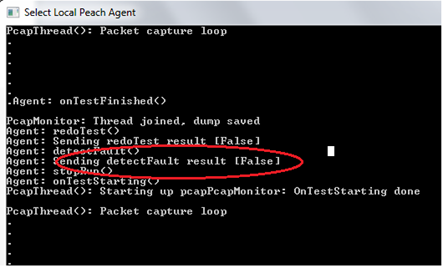
- Loggers
Peach, by default has a logging mechanism which is a single file system logger and can be extended with the help of Python class (if you want to) to log anything.
Logger would log into the specified path mentioned in the parameter "path" and until a fault is detected, very little information is logged, in order to conserve disk space.
[sourcecode]
[/sourcecode]
Sample log file would be as shown below:
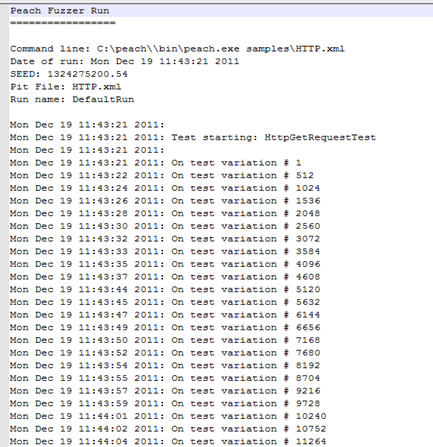
- Analysis
Further analysis can be done with the help of different logs and faults generated with the help of different publishers/agent/monitor.
Conclusion:
Just "Fuzz" it, because if you don't – someone else will.
References:
11 courses, 8+ hours of training

11 courses, 8+ hours of training

In this Series
- Fuzzing – Application and File Fuzzing
- DevSecOps: Moving from “shift left” to “born left”
- What’s new in the OWASP Top 10 for 2023?
- DevSecOps: Continuous Integration Continuous Delivery (CI-CD) tools
- Introduction to DevSecOps and its evolution and statistics
- MongoDB (part 3): How to secure data
- MongoDB (part 2): How to manage data using CRUD operations
- MongoDB (part 1): How to design a schemaless, NoSQL database
- Understanding the DevSecOps Pipeline
- API Security: How to take a layered approach to protect your data
- How to find the perfect security partner for your company
- Security gives your company a competitive advantage
- 3 major flaws of the black-box approach to security testing
- Can bug bounty programs replace dedicated security testing?
- The 7 steps of ethical hacking
- Laravel authorization best practices and tips
- Learn how to do application security right in your organization
- How to use authorization in Laravel: Gates, policies, roles and permissions
- Is your company testing security often enough?
- Authentication vs. authorization: Which one should you use, and when?
- Why your company should prioritize security vulnerabilities by severity
- There’s no such thing as “done” with application security
- Understanding hackers: The insider threat
- Understanding hackers: The 5 primary types of external attackers
- Want to improve the security of your application? Think like a hacker
- 5 problems with securing applications
- Why you should build security into your system, rather than bolt it on
- Why a skills shortage is one of the biggest security challenges for companies
- How should your company think about investing in security?
- How to carry out a watering hole attack: Examples and video walkthrough
- How cross-site scripting attacks work: Examples and video walkthrough
- How SQL injection attacks work: Examples and video walkthrough
- Securing the Kubernetes cluster
- How to run a software composition analysis tool
- How to run a SAST (static application security test): tips & tools
- How to run an interactive application security test (IAST): Tips & tools
- How to run a dynamic application security test (DAST): Tips & tools
- Introduction to Kubernetes security
- Key findings from ESG’s Modern Application Development Security report
- Microsoft’s Project OneFuzz Framework with Azure: Overview and concerns
- Software maturity models for AppSec initiatives
- Best free and open source SQL injection tools [updated 2021]
- Pysa 101: Overview of Facebook’s open-source Python code analysis tool
- Improving web application security with purple teams
- Open-source application security flaws: What you should know and how to spot them
- Android app security: Over 12,000 popular Android apps contain undocumented backdoors
- 13 common web app vulnerabilities not included in the OWASP Top 10
- Fuzzing, security testing and tips for a career in AppSec
- 14 best open-source web application vulnerability scanners [updated for 2020]
- 6 ways to address the OWASP top 10 vulnerabilities
- Ways to protect your mobile applications against hacking

Get certified and advance your career
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, (ISC)², Cisco, Microsoft and more!

Application security
Application security
Application security
DevSecOps: Continuous Integration Continuous Delivery (CI-CD) tools
Application security